

1. 서 론
2. 태양광 전압, 전류 추론을 위한 회귀 모델
2.1 데이터 전처리 및 학습 데이터 생성을 위한 수학적 모델
2.2 성능 추론을 위한 회귀 모델의 구성 및 학습
3. 태양광 고장진단을 위한 분류 모델 제안
3.1 분류 모델 학습을 위한 고장데이터 생성
3.2 생성된 고장데이터 셋을 이용한 분류 모델의 학습 및 검증
3.3 시험데이터를 이용한 학습된 분류 모델 평가
4. 결 론
1. 서 론
최근 기후변화 대응과 탄소중립 실현을 위한 에너지 전환 정책의 하나로, 태양광발전소의 건설이 급속히 확대되고 있고, 국내 태양광 설비 누적 설치량은 2024년 기준 27.1 GW에 달한다. 국내의 경우 산업용 전기요금의 상승과 RE100 기업의 증가로 산업단지 또는 공장 지붕을 활용한 태양광발전 설비가 증가하고 있으며, 신재생에너지공인인증서(REC)의 가중치가 1.5로 발전사업 측면에서도 매혹적인 부분이 있어 확산이 증가하고 있다.
그러나 이러한 지붕형 태양광 설비는 설치 구조물의 다양성, 접근성 제약, 주변 환경 조건의 불균일성 등으로 인해 유지보수 및 운영관리(O&M) 측면에서 어려움이 존재한다1). 태양광 발전설비는 일사량, 온도, 풍하중, 먼지 퇴적 등 다양한 외부 요인에 지속적으로 노출되어 있으며, 특히 지붕형 설비의 경우 구조물 진동, 누적 열화, 배선 접속 불량 등 입지 다변화형 특성으로 인한 고장 발생률이 높게 보고되고 있다. 다수의 사업장은 전문 엔지니어의 정기 점검이 이루어지지 않거나, 설비 접근이 어려워 실시간 모니터링이 불충분한 실정이다2). 이러한 관리 미비로 인한 발전효율 저하는 장기적으로 에너지 생산 손실뿐 아니라, 인버터 및 모듈 수명 단축, 유지보수 비용 증가 등 운영 경제성 악화로 이어진다.
기존의 고장진단 방법은 주로 인버터 알람이나 단순 발전량 비교를 통해 이상 여부를 판단하는 방식으로, 정량적 근거가 부족하고 환경 변수의 복합적인 영향을 반영하지 못하는 한계를 가진다. 특히 여러 인버터가 병렬로 구성된 대규모 어레이에서는 각 설비 간의 출력 차이가 발생하더라도 단순 시점 비교로는 정상과 고장을 구분하기 어려운 문제가 있다. 공장 지붕 옥상에 설치됨에 따라 구조물의 음영 발생 등으로 각 설비 간 발전량의 차이가 크게 발생할 수도 있다3).
최근 데이터 기반의 인공지능 분석기술을 활용하여 고장진단을 하기 위한 다양한 연구 등이 수행되고 있다4). 그러나, 국내 태양광발전소에서 수집되는 데이터 셋에 대한 표준화가 정립되어 있지 않은 상태며, 모니터링 社나 운영기관에 따라 데이터 기록 관리도 달라 데이터 셋을 분석하는 데 어려움이 있다. 대부분의 발전소에서는 환경 센서 데이터를 확보하고 있지 않아 정밀한 분석에 한계가 존재한다. 이러한 한계를 극복하기 위해 태양광 발전설비의 물리적 모델값을 인공지능 모델의 입력변수로 활용해 DC 어레이 전압 및 전류를 추론의 정확도를 95% 이상 정확히 추론 가능한 알고리즘이 제시되었다5,6). 일반적으로 환경 센서인 일사량이나 온도센서 데이터와 DC 어레이 전압이 선형적인 특성이 매우 낮은 항목으로, 피어슨 상관관계 분석에도 상관성이 낮다는 분석 결과를 확인할 수 있다.
본 논문에서는 인공지능 모델을 통해 환경 센서 데이터를 기반으로 DC 어레이 전압 추론 정확도를 매우 높게 추론한 연구 결과를 이용하여 고장진단 방법을 제안하고자 한다. 국내 태양광발전소 대부분이 모듈별 센서나 고해상도 데이터 수집 시스템을 구축하지 못하고 있기에, 실 운영 중 수집한 데이터 셋을 기반으로 하는 고장진단 분석 방법이 필요하다. 본 논문에서는 인버터 단위로 수집되는 전압·전류 데이터뿐 아니라, 온도·일사량 등 환경 요인을 함께 고려하여 과거 고장발전소로부터 수집한 데이터의 고장의 유형별 패턴을 전압-전류 좌표평면으로 분류하고, 전압, 전류 인공지능 추론모델값과 인버터로부터 수집된 값의 비에 따라 어떤 고장인지 추론하는 분류 학습 모델을 제안하였다. 제안된 분류 학습 모델을 2개의 3 kW급 태양광 시스템에 적용하고 고장을 모의하여 정확도를 평가하였다. 제안하는 분류 모델 기반 고장진단 방법은 향후 국내 태양광 O&M의 기술 고도화에 중요한 기술적 기반을 제공할 것으로 기대된다.
2. 태양광 전압, 전류 추론을 위한 회귀 모델
2.1 데이터 전처리 및 학습 데이터 생성을 위한 수학적 모델
Shin et al. (2025)5)의 논문에서 태양광 어레이에 대한 수학적 모델링은 식(1)과 같이, 단일 다이오드 모델(Single-Diode Model, SDM)을 사용한다. 이 모델은 광전류(), 다이오드 전류(), 직렬저항(), 병렬저항()의 상호 작용으로 출력전류()를 계산한다.
식 (1)을 이용하여 일사량과 모듈 온도에 따른 최대 전압과 전류의 변화 특성과 태양광 모듈의 직·병렬 연결 수를 반영한 수식은 식(2), (3)과 같다.
여기에, 태양광 모듈의 설치 연수에 따른 성능 저하율을 고려하면 식(4), (5)와 같다.
본 논문에서는 위의 수학적 모델을 분류 모델의 학습 데이터 생성 및 회귀 모델의 데이터 전처리, 학습 데이터 생성에 활용하였다.
2.2 성능 추론을 위한 회귀 모델의 구성 및 학습
회귀 모델의 입력 변수는 일사량, 모듈 온도, 수학적 모델을 기반으로 계산된 DC 전압과 전류, 시간정보(month, hour)이며, 출력 변수는 DC 전압과 전류, AC 출력이다. 총 7종의 회귀 모델(linear, neural, tree, LSK, GPR, boosted, bagging tree)을 MATLAB 2022a 환경에서 학습 및 검증을 실시하였으며, 학습·검증 데이터 비율은 7:3으로 분할하였다. 각 모델에 대한 성능평가 지표는 R2 (Coefficient of Determination), NRMSE (Normalized Root Mean Square Error), RMSE (Root Mean Square Error), MAE (Mean Absolute Error), MSE (Mean Square Error)를 사용하였다. 모든 모델에서 DC 전압 및 전류의 성능평가 지표는 매우 높게 나타났으며, 특히 Bagging Tree 모델의 경우, DC 전압의 은 0.9666, DC 전류의 은 0.9987로 가장 우수한 성능을 보였다. 이 모델을 이용한 월별 추론 결과,실측값 대비 오차율 0.07% 이내로 유지되어 실제 운영 중인 발전소에서도 적용할 수 있음을 입증했다. 본 논문에서는 고장진단 모델 생성을 위해, DC 전압과 전류를 추론하는 과정에서 앞서 제시한 학습 방법과 회귀 모델(Bagging Tree 모델)을 활용하였다.
3. 태양광 고장진단을 위한 분류 모델 제안
3.1 분류 모델 학습을 위한 고장데이터 생성
태양광의 출력을 추론하는 것은 발전소가 정상적으로 동작하고 있는지, 혹은 출력 저하가 발생했는지를 판단하는데는 유용하지만, 세부적인 고장진단에는 한계가 있다7,8). 따라서, 출력 대신 전압과 전류의 비를 활용하면, 전압과 전류의 상대적 감소를 통해 보다 구체적인 고장진단이 가능하다9,10). 본 논문에서 제안하는 태양광 고장진단 방법은 인버터의 DC 전압과 전류의 위치를 이용하는 것으로, 태양광 DC 어레이가 고장인 상태에서 인버터에서 수집된 데이터가 필요하다. 하지만, 국내 상황상 인버터에서 수집된 다량의 고장데이터가 없으므로, 약 10년간 태양광발전소 현장 진단을 통해 수집된 1,849개의 정상/고장 I-V 곡선 데이터, 일사량 및 모듈 온도 데이터를 활용하였다.
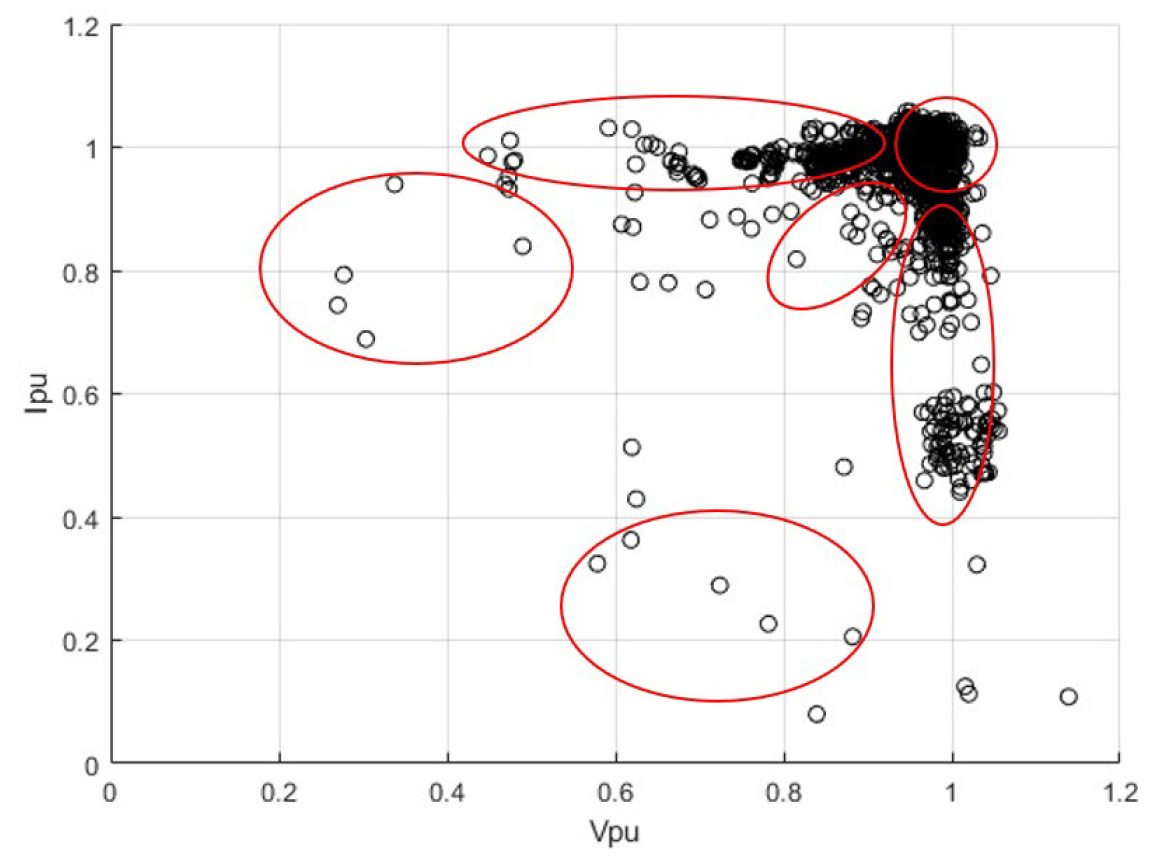
측정된 I-V 곡선의 최대 출력 점 데이터를, 측정 시점의 일사량과 모듈 온도를 이용해 시뮬레이션 된 I-V 곡선의 최대 출력 점 데이터로 나누면, Fig. 1과 같이 PU (Per-Unit) 단위로 나타낼 수 있다. Fig. 1을 보면, PU 단위의 전압과 전류는 일정 범위 내에서 군집화 되었다. 예를 들어 1, 1 중심으로 군집화된 데이터는 정상상태의 데이터를 의미하며, 왼쪽과 아래쪽의 데이터는 각각 전압과 전류만 감소한 고장 상태를 의미한다. 이처럼 전압과 전류의 위치를 이용하면 태양광 DC 어레이에 대한 정상과 고장에 대한 진단이 가능하며, 나아가 어떤 고장인지도 구분이 가능하다.
추가로, 옥외에 설치되는 일사량계는 태양광 모듈과 마찬가지로 표면에 오염이 발생할 수 있다. 일사량계 오염과 관련된 전압과 전류의 특성을 확인하기 위해, Fig. 2의 왼쪽과 같이 투과도 70%인 투과 필름을 일사량계 위에 붙여 오염 상태를 모의하였다. 이 상태에서 수집된 데이터를 PU 단위의 전압과 전류로 정규화하면, Fig. 2의 오른쪽과 같이 나타낼 수 있다. 전압은 0.9 ~ 1의 범위에, 전류는 1를 초과하는 영역에 주로 분포하였다. 이는 일사량계에 오염이 발생하면, 실제 보다 낮은 일사량이 측정되어 이를 이용하여 시뮬레이션 되는 전륫값이 낮아지기 때문이다. 분포된 데이터들은 빨간색 타원형으로 표시된 범위 내에서 군집화되는 경향을 확인하였다.
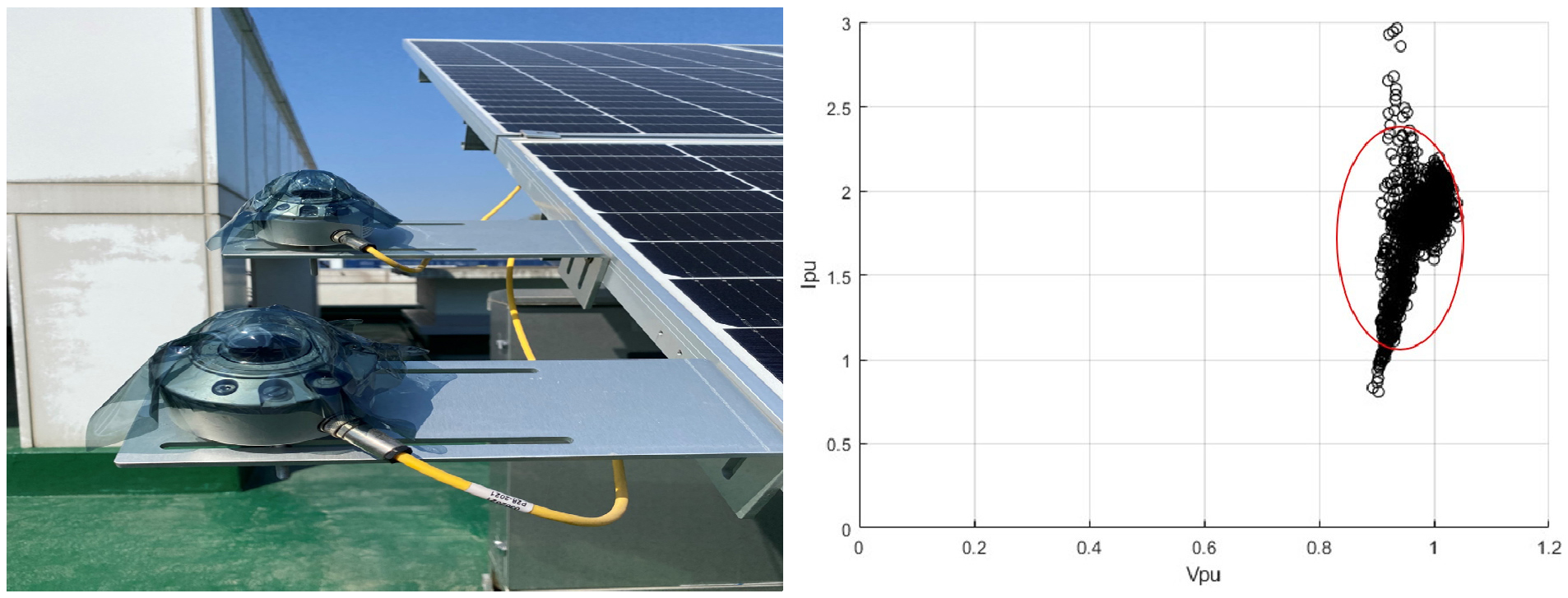
Fig. 1과 Fig. 2에서 수집 및 분석된 데이터를 기반으로, 고장진단 분류 모델 학습을 위해 구성된 데이터셋은 Fig. 3과 같다. Fig. 3의 x축은 측정 전압을 추론 전압으로 나눈 값이며, y축은 측정 전류를 추론 전류로 나눈 값이다. 발전소에서 측정된 현장 데이터와 실험 데이터만 학습에 활용할 경우, 데이터의 양이 충분하지 않고 분포가 불균형하며, 일부 구간에서는 노이즈가 존재하는 문제가 있었다. 이러한 문제를 보완하기 위해 데이터를 재구성하였으며, 이를 통해 고장 코드별 데이터의 분포 범위를 균일하게 확보하고, 학습 안정성을 향상할 수 있다.
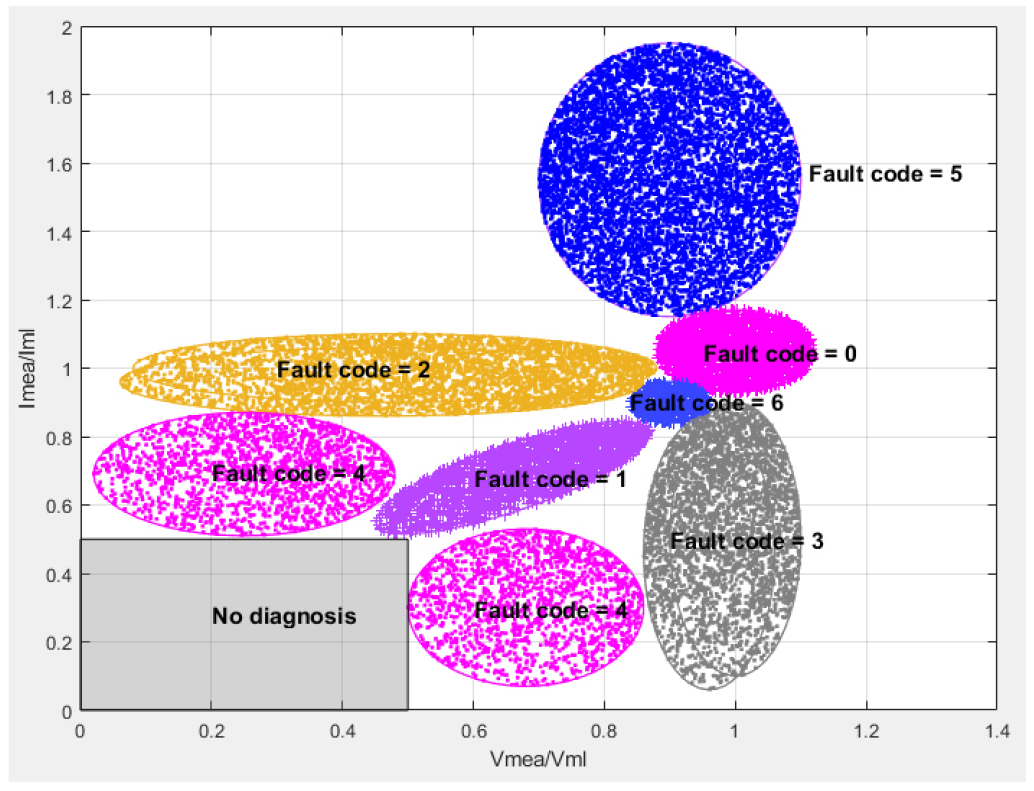
고장 코드는 정상을 포함하여 Table 1과 같이 6개로 구분하였다. 고장 코드 0은 정상이며, 고장 코드 1은 PID (Potential Induced Degradation)현상과 같은 태양광의 충진율이 크게 감소하는 고장이다. 고장 코드 2는 전압 불균일 현상으로 바이패스 다이오드 고장, 바이패스 다이오드가 동작한 음영, 온도센서 이상 등이 포함된다. 고장 코드 3은 전류 불균일 현상으로 바이패스 다이오드가 동작하지 않은 음영, 태양광 모듈 간의 설치 각도 차이, 태양광 스트링 퓨즈 용단 등이 포함된다. 고장 코드 4는 태양광 스트링 내 넓은 범위의 태양광 모듈 음영이며, 고장 코드 5는 일사량계 오염이다. 마지막으로 고장 코드 6은 태양전지, EVA 등 태양광 모듈의 구성 부재 열화를 나타내는 고장이다.
Table 1
Categories of fault codes
| Fault code | Fault description |
| 0 | Normal |
| 1 | PID (FF significantly decreased) |
| 2 | Voltage mismatch |
| 3 | Current mismatch |
| 4 | Partial shading |
| 5 | Pyranometer soiling |
| 6 | Degradation of PV module component |
3.2 생성된 고장데이터 셋을 이용한 분류 모델의 학습 및 검증
Fig. 3의 고장데이터 셋을 이용하여 다양한 지도 학습 기반의 분류 모델을 학습 및 검증하였다. 입력변수는 전압비(측정 전압/추론 전압), 전류비(측정 전류/추론 전류)이며, 출력 변수는 고장 코드(0 ~ 6)이다. 전체 고장데이터의 개수는 23,777개이며, 이 중 70%는 학습 데이터, 30%는 검증 데이터로 활용하였다. 분류 모델의 학습과 검증에는 Matlab Tool box 중 분류 학습기를 사용하여, 트리(Tree) 모델, 판별 분석(Discriminant Analysis) 모델, 나이브 베이즈(Naive Bayes) 모델, 서포트 벡터 머신(Support Vector Machine, SVM) 모델, 최근접 이웃(K-Nearest Neighbor, KNN) 모델을 학습 및 검증하였다.
분류 모델 기반의 태양광 고장진단의 구성도는 Fig. 4와 같다. 인버터로부터 수집된 실측 데이터(DC 전압, 전류)와 회귀 모델로 추론된 데이터(DC 전압·전류)의 비율을 입력값으로 사용하며, 이를 통해 실시간으로 고장 상태를 분류할 수 있다. 이러한 방법을 플랫폼에 적용하면 전압–전류 2차원 분포도 상에서 실시간 인공지능 분석 결과를 시각화함으로써, 각 시점의 시스템 상태를 직관적으로 확인할 수 있다.
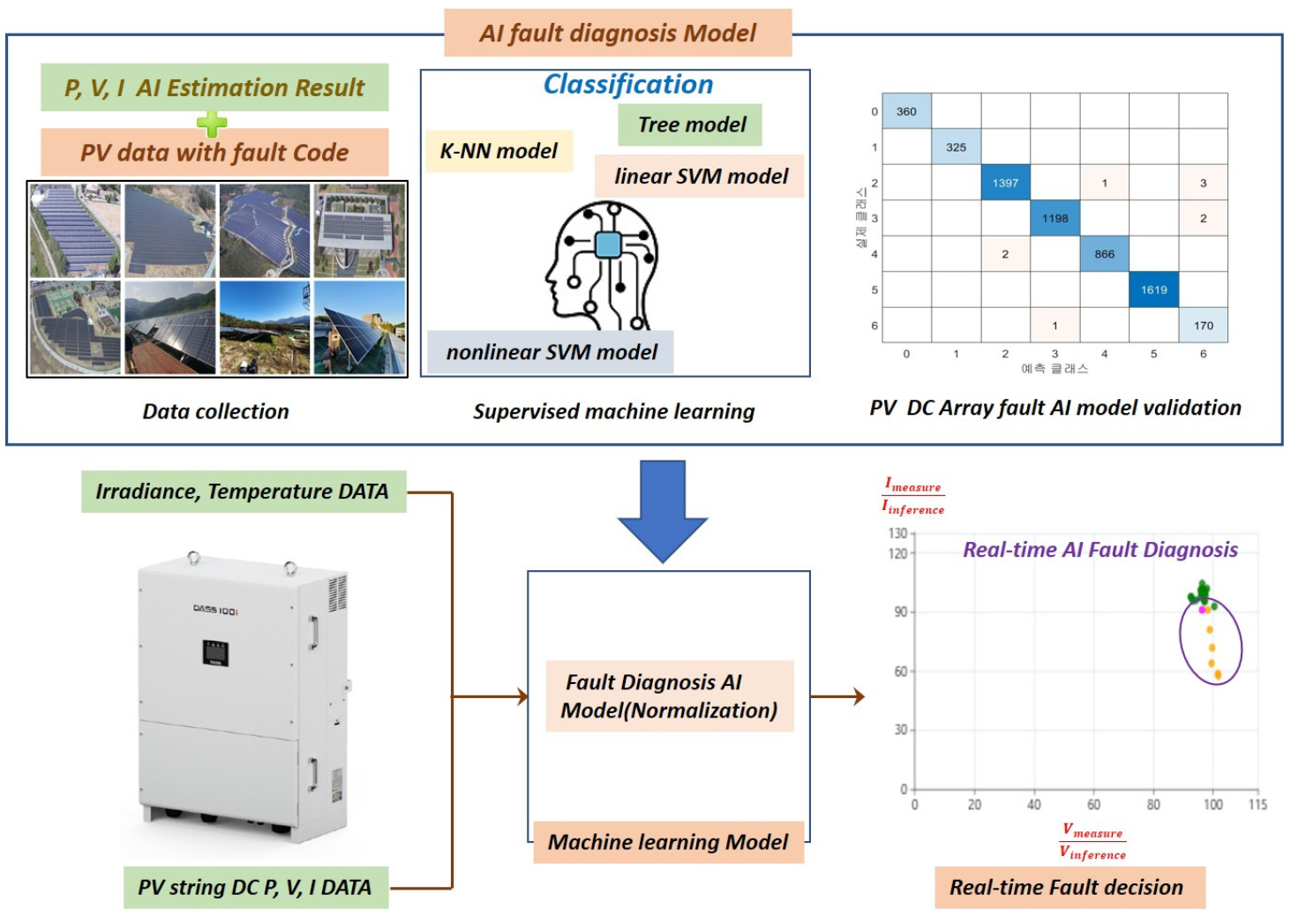
Table 2는 검증 데이터를 이용하여 5가지의 분류 모델의 정확도를 비교한 결과이다. 모든 모델의 검증 정확도는 98% 이상으로 전반적으로 높은 수준을 보였다. 이러한 높은 정확도는 학습 및 검증 데이터 셋에서 고장 코드 별 데이터가 명확히 구분되어 있으며, 이를 기반으로 효과적인 지도 학습이 이루어졌기 때문이다. 이 중 정확도 가장 높은 모델은 최근접이웃 모델로 검증 정확도는 99.8%였으며, 가장 낮은 모델은 나이브 베이즈 모델로 검증 정확도는 98.1%였다.
Table 2
Validation accuracy for each classification model
| Classification model | Validation accuracy [%] |
| Tree model | 99.7 |
| Discriminant analysis model | 98.7 |
| Naive Bayes model | 98.1 |
| Support vector machine model | 98.3 |
| K-nearest neighbor model | 99.8 |
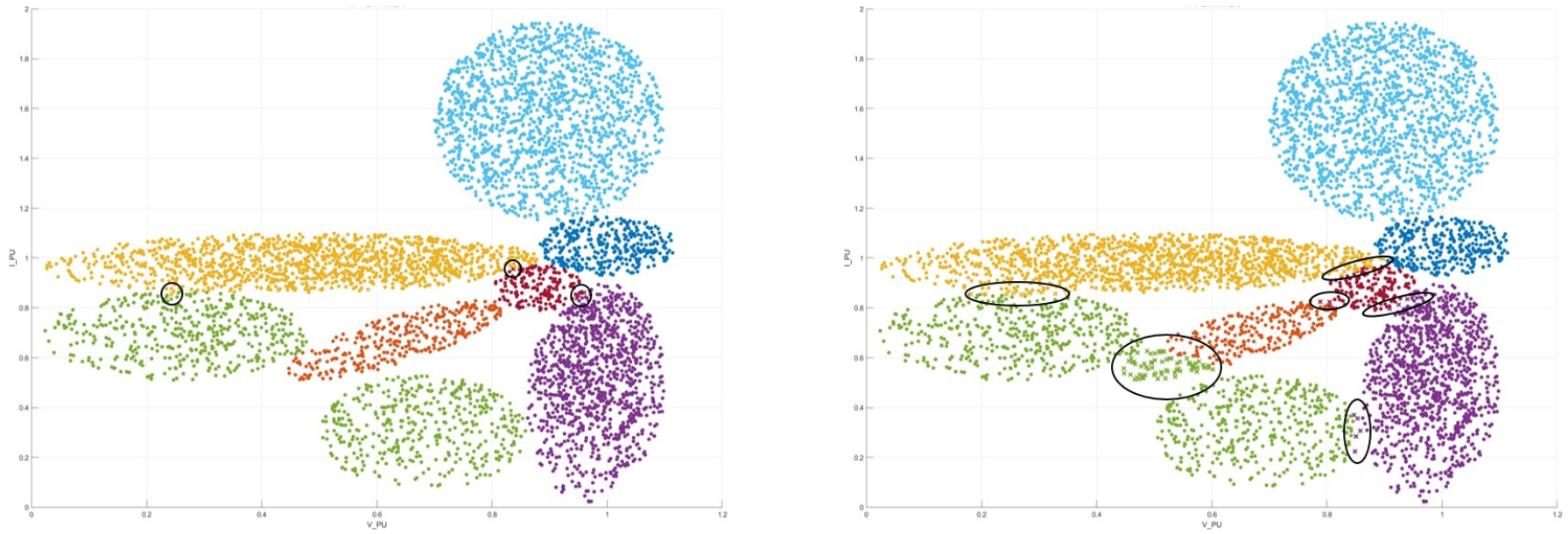
보여지는 수치 외에 검증 데이터가 어떻게 분류되었는지 확인하기 위해, Fig. 5와같이 산점도 플롯을 이용하여 최근접 이웃 모델과 나이브 베이즈 모델을 비교하였다. 왼쪽의 최근접이웃 모델은 세 구역(Fig. 5의 검은색 동그라미)에서 각 3개의 데이터가 오분류된 것으로 나타났다. 반면, 오른쪽의 나이브 베이즈 모델은 여섯 구역에서 최소 5개 이상의 데이터가 오분류되었으며, 특히 고장 코드 1의 하단 영역에서 약 60개의 데이터는 고장 코드 4로 오분류 되었다. 이를 통해 최근접이웃 모델이 데이터 간의 경계를 보다 보다 정확하게 구분하여 높은 정확도를 달성한 것으로 해석되며, 본 논문에서는 최근접이웃 모델을 고장진단 모델로 사용하였다.
3.3 시험데이터를 이용한 학습된 분류 모델 평가
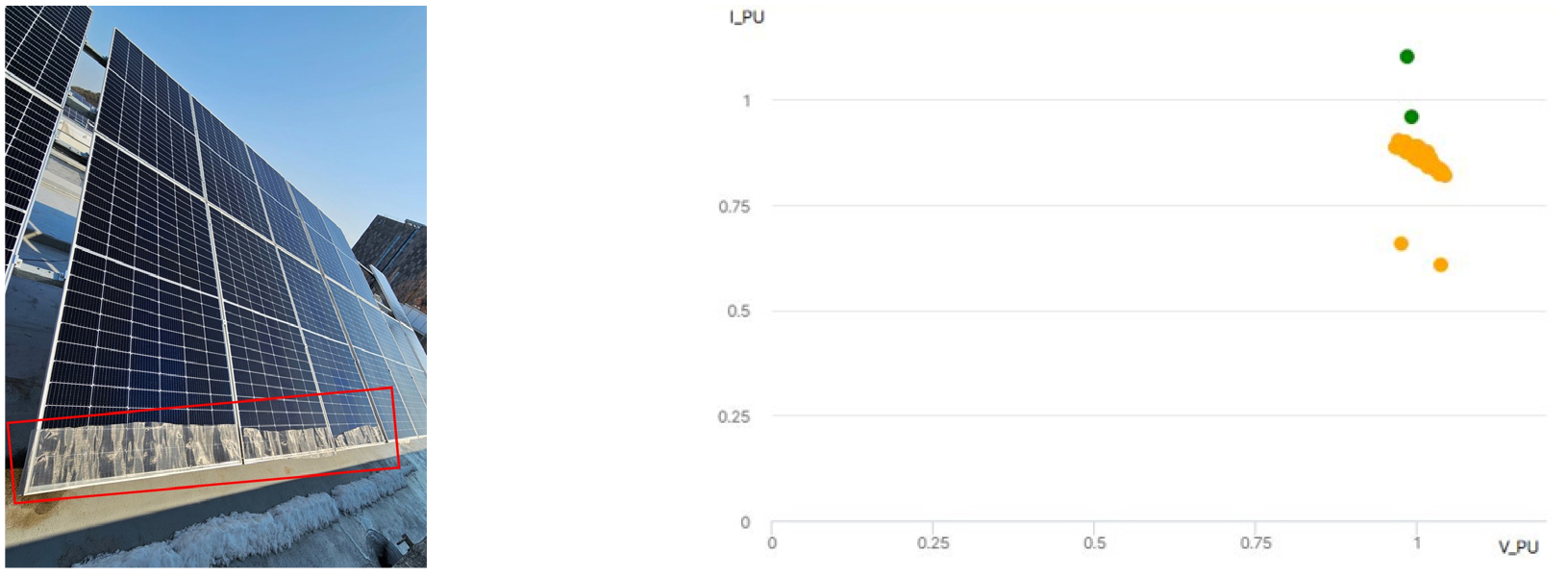
학습 및 검증된 최근접이웃 모델의 성능에 대한 추가 평가를 위해, 3 kW급 태양광 시스템 2곳에서 고장을 모의하여 데이터를 수집하였다. 모의된 고장은 전압과 전류 불균일이며, 전압과 전류 비를 이용한 고장진단의 기본 원리를 검증하고, 실제 시스템의 영향을 최소화하기 위해 선택하였다. 이를 반영하여 모의된 첫 번째 고장은 전류 불균일으로, Fig. 6의 왼쪽과 같이 모듈 하단부에 메쉬를 덮어 모의하였다. 이 고장은 태양광 모듈 하단부에 음영 또는 오염이 발생한 상태를 가정한 것이다. 데이터 수집일은 25년 3월 19일이며, 고장 모의 시간은 9:20 ~ 12:10이다. 저일사량에서는 정상과 고장에 따른 출력 차이가 크지 않아, 일사량이 300 W/m2 이상에서 수집된 데이터만 분석에 사용하였으며, 데이터 샘플은 1분 평균이다.
고장진단 모델에 대한 성능 평가는 혼동행렬을 이용하였으며, 혼동행렬의 구조는 아래의 Table 3과 같이 표현된다. 이를 바탕으로 식(6)을 적용하여 정확도를 계산하였다.
모의된 고장으로 인한 태양광의 출력 특성은 전류가 감소한 형태이며, 고장 코드 3으로 분류된다. Fig. 6의 오른쪽과 같이 고장 코드 3은 주황색 동그라미이며, 초록색 동그라미는 정상을 나타낸다. 실험 시간 동안 수집된 데이터는 총 151개이며, 이 중 고장 코드 3으로 정확히 분류된 데이터는 149개, 정상으로 오분류된 데이터는 2개이다. Table 4와 식(6)을 이용하여 계산한 결과, 정확도는 98.7%였다.
Table 4
Confusion matrix for fault code 3 (current mismatch)
| Actual class | |||
| Normal | Fault code 3 | ||
| Predicted class | Normal | – | 2 |
| Fault code 3 | – | 149 | |
두 번째로 모의된 고장은 전압 불균일으로, Fig. 7의 왼쪽과 같이 모듈 오른쪽 하단부에 투과 필름을 부착하여 모의하였다. 이 고장은 태양광 모듈에 부분 음영인 상태를 가정한다. 데이터 수집일은 25년 3월 19일이며, 고장 모의 시간은 12:20 ~ 15:10이다.
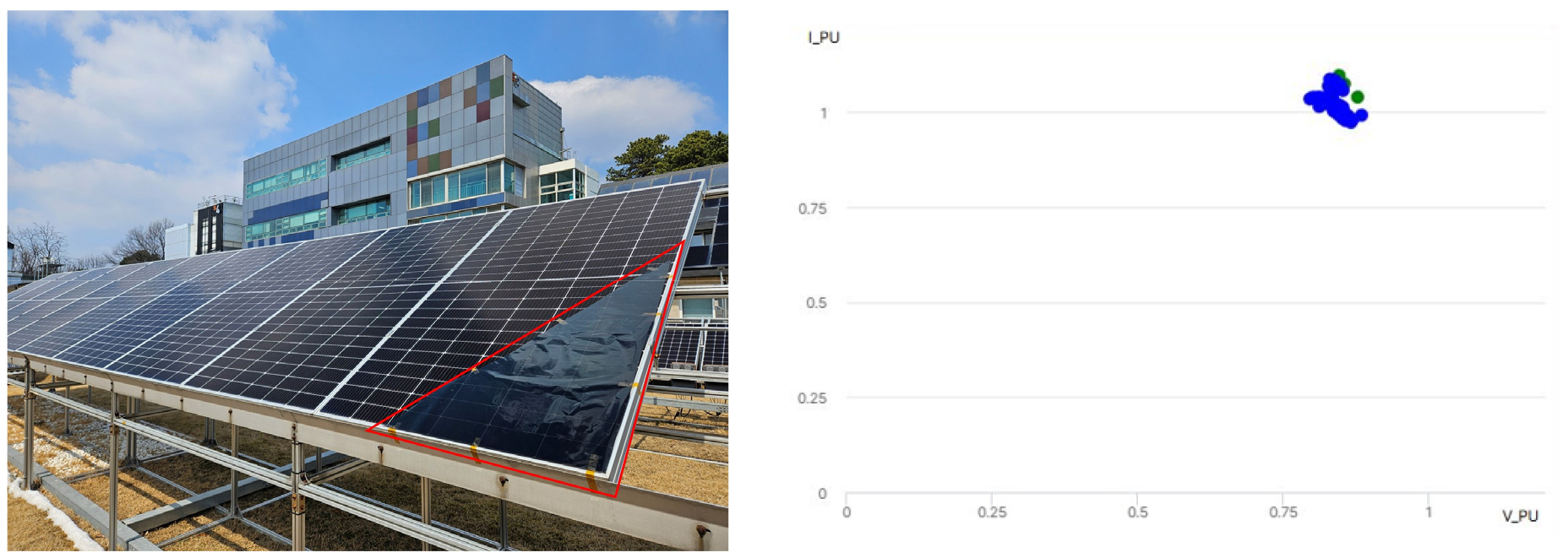
모의된 고장으로 인한 태양광의 출력 특성은 전압이 감소한 형태이며, 고장 코드 2로 분류된다. Fig. 7의 오른쪽과 같이 고장 코드 2는 파란색 동그라미이며, 초록색 동그라미는 정상을 나타낸다. 실험 시간 동안 수집된 데이터는 총 135개이며, 이 중 고장 코드 2로 정확히 분류된 데이터는 132개, 정상으로 오분류된 데이터는 3개이다. Table 5와 식(6)을 이용하여 계산한 결과, 정확도는 97.8%였다.
4. 결 론
본 논문은 태양광 DC 어레이의 고장진단을 위해 인버터 수집 데이터와 분류 모델을 이용하였다. 고장진단의 선행 조건인 정상상태를 추론하는 방법은 일사량 및 온도 변화에 따른 태양광의 출력 특성을 반영한 수학적 모델 및 이를 이용한 회귀 모델을 이용한 전압과 전류 추론 모델을 사용하였다. 태양광 고장진단 모델은 지도 학습 기반의 분류 모델을 사용하였다. 모델 학습에 필요한 데이터는 수집된 약 1,800여개의 I-V 곡선 데이터의 최대 출력 점 데이터와 고장을 모의하여 인버터에서 수집된 데이터를 사용하였다. 생성된 데이터셋을 이용하여 5종의 분류 모델(트리 모델, 판별 분석 모델, 나이브 베이즈 모델, SVM 모델, KNN 모델)을 학습 및 검증하였다. 성능이 가장 우수한 모델은 KNN 모델이었으며, 고장 모의 실험을 통해 수집된 데이터를 이용하여 정확도를 평가한 결과 평균 98.25%였다.
이러한 진단 결과는 인버터 수집 데이터에 일사량 및 온도 데이터를 결합한 인공지능 모델(회귀 및 분류 모델)의 학습을 통해 높은 정확도로 태양광 DC 어레이에 대한 고장진단이 가능함을 보여주었다. 본 기술을 태양광발전소의 O&M 활동의 효율화를 위한 의사결정 지원 도구로 활용할 수 있으며, 향후에는 대용량 태양광발전소에 적용하여 모델의 정확도와 활용 방안을 검증할 예정이다.
