

기호 및 약어 설명
NMAE : Normalized Mean Absolute Error, 예측시장에 참여하기 위한 정확도 식(%)
NOAA : National Oceanic and Atmospheric Administration, 미국 해양 대기청
GFS : Global Forecast System, 세계 기후 예보 시스템
LSTM : Long Short-Term Memory
D : Day, 하루를 초로 환산(86,400초)
T : 현재 날짜를 유닉스 시간으로 환산(초)
A :Actual, 실제 발전량(kWh)
F : Future, 예측 발전량(kWh)
C :Capacity, 태양광 설비용량(kw)
M : Min Capacity, 설비용량의 10%의 발전을 만족하는 시간대별 실제 태양광 발전량의 합(kWh)
R : Reward, 정산금(\)
MAX : 예측시장 참여시 받게 되는 최대 정산금(\)
W : Weight, 가중치 행렬
: Input vector, 모델 입력 벡터 값
: hidden vector, 모델 은닉 벡터 값
: input gate, cell 입력 게이트
: forget gate, cell 망각 게이트
: output gate, cell 출력 게이트
: gate gate, cell candidate values
: cell state, cell 값
1. 서 론
정부의 에너지 전환 정책을 반영한 ‘재생에너지 3020 이행계획’에 따르면 2030년까지 재생에너지의 발전비 중 목표를 20%1)로 설정하고 있어, 향후 재생에너지의 발전 비중은 가파른 상승세를 이어갈 것으로 예상된다. 하지만, 재생에너지에 의해 생산된 전력은 기존의 발전원에 비해 전력생산의 변동성이 크기 때문에 재생에너지 발전비 중 확대에 따라 전력 수급 과정에서 다양한 문제들이 발생할 수 있다2).
신재생에너지는 지구환경에 영향을 크게 받기 때문에 안정적인 전력계통을 운영하기 위해서는 신재생에너지로 발전할 수 있는 발전량을 정확하게 예측하여야 한다. 신재생에너지의 정확한 발전량 예측은 불필요한 전력생산 과잉을 방지하며 이에 따른 불필요하게 소비되는 자원 낭비를 줄일 수 있다.
산업통상자원부와 한국전력거래소는 재생에너지 확대에 따른 출력 변동성 대응을 위해 재생에너지 발전량 예측제도를 도입한다고 밝혔고 2021년 10월부터 예측제도가 시행되었다3). 예측제도는 20 MW 이상의 재생에너지 발전량의 예측 정확도가 92% 이상 이게 되면 이에 따른 정산금을 받게 된다. 예측제도에 참여하기 위해서는 20 MW 이상 태양광 및 풍력 발전 사업자 또는 1 MW 이하 태양광 및 풍력을 20 MW 이상 모집한 집합 전력자원 운영자(소규모 전력 중개사업자) 중에서 1개월 동안 평균 예측오차율이 10% 이하를 달성하게 되면 예측제도에 참여할 수 있다3).
본 연구에서는 발전량 예측시장 참여를 위하여 쉽게 접할 수 있는 한국 기상청의 공공 기상예보 데이터를 사용하여 이후의 시간대별 태양광 발전량을 예측하는 기법을 소개하고 한국전력거래소에서 운영하는 태양광 예측시장에 참가하기 위하여 정확도 90% 이상을 목표와 예측 결과에 따른 정산 성공률에 대하여 분석한다.
예측에 사용된 모델은 LSTM 기반의 모델이며 마지막 출력계층에서는 평균 계층을 사용하여 3개의 LSTM 모델의 출력을 결합하여 평균을 산출한다.
본 연구 결과는 LSTM 기반 앙상블 모델을 사용하여 예측제도에 참가할 수 있도록 하고 예측제도에 참여할 수 있더라도 예측 정산금이 정확도와 무관하게 적용될 수도 있다는 것을 보여주며 한국 기상청의 공공 데이터 외 해외 기상청 공공 데이터 수집 방법을 제시하여 더 높은 정확도 산출에 도움을 주고자 한다.
2. 태양광 발전량 예측 알고리즘
2.1 데이터 전처리 및 분석
태양광 발전량 데이터는 발전 사업자 A의 태양광 발전량 수집 센서를 통하여 데이터를 수집하였고 예측에 필요한 기상 데이터는 한국 기상청의 기상예보 데이터를 사용하였다.
한국 기상청의 단기 예보는 지역별 시간별 차이로 인한 수요자의 불편을 최소화하기 위해 전국을 5 km*5 km 간격의 격자로 나누어 읍, 면, 동 단위의 행정구역 중심으로 상세한 날씨를 제공합니다. 2021.6.29.부터 단기 예보 생산체계 개선에 따라, 예보 시간 상세화(기존 3시간→1시간, 강수량/신적설 포함) 및 예보 기간 확장(글피 추가)된 자료를 제공하고 있습니다. 따라서 본 연구는 개편된 단기 예보 데이터를 사용하였다4).
예보 데이터를 추출한 방법은 단기 예보 데이터에서 예보발표 시간이 05시(UTC)를 기준인 것으로 24시간 예보된 데이터를 사용하였다. 기상청 단기 예보 데이터의 시간은 UTC 기준이므로 기존 예보 데이터 시간에서 9시간을 더하여 작업을 진행하였다. Fig. 1에서는 2022년 1월 22일의 예보 데이터를 가공하기 위해서 2022년 1월 21일의 예보발표 05시의 시간대를 기준으로 +10에서부터 +33시간까지의 예보 데이터를 가져왔다. 초록색 네모 상자 +10부터 +33은 최종적으로 2022년 1월 22일의 예보 데이터가 된다. 파란색 네모 상자도 마찬가지이다. 단기 예보 데이터는 총 7개의 데이터이며 Table 1과 같다. 최종적으로 사용된 데이터 기간은 2022년 1월 22일부터 2022년 7월 31일까지 데이터이며 6월 25일부터 7월 4일은 데이터 결측으로 인하여 제거하였다. 기상예보데이터는 Table 1와 같다.
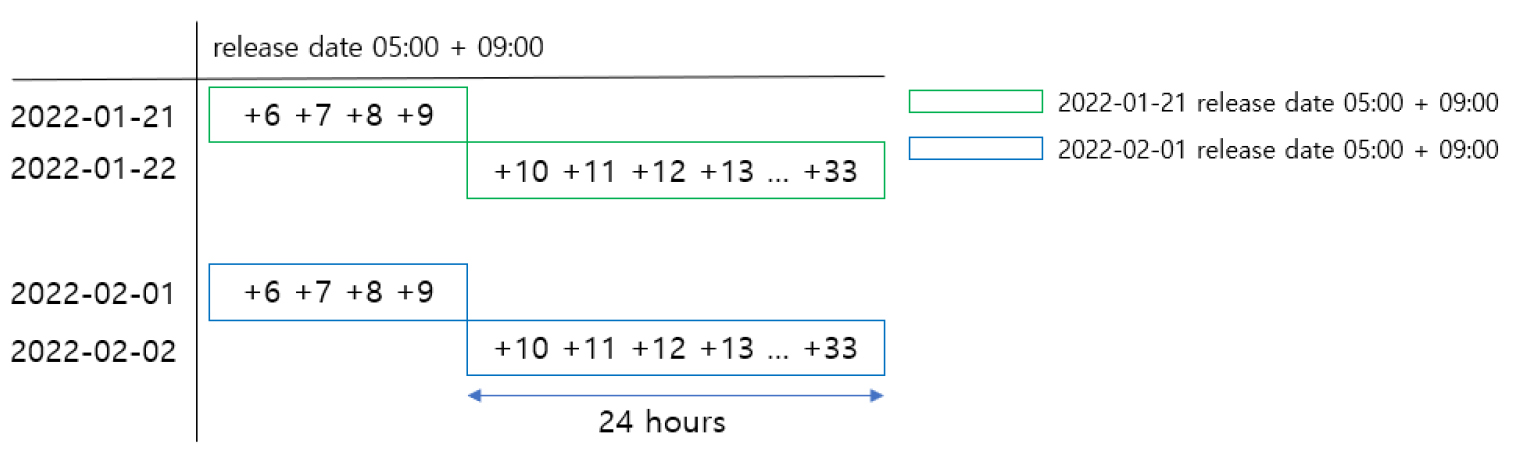
Table 1
Korea Meteorological Administration short-term forecast data
예보 데이터를 범주형 데이터와 수치형 데이터로 나눠 범주형 데이터는 원핫 인코딩을 사용하여 파생변수를 생성한다. 예보 데이터에서 범주형 데이터는 강수형태(pty)와 하늘 상태(sky)이다. 강수 형태의 값은 0:없음, 1:비, 2:비/눈, 3:눈, 4:소나기이며 하늘 상태의 값은 1:맑음, 3:구름 많음, 4:흐림이다. 강수량(pcp)은 버킷 데이터이며 1 mm 미만과 1 mm 이상 30 mm 미만은 정수로 표기한다. 이 데이터에서 강수량은 모두 30 mm 미만이므로 1 mm 미만은 “0” 1 mm 이상은 “1”로 치환하였다.
시간 데이터는 주기함수로 치환하여 준다. Day_sin은 식(1)과 같다. Day_cos는 식(2)와 같다.
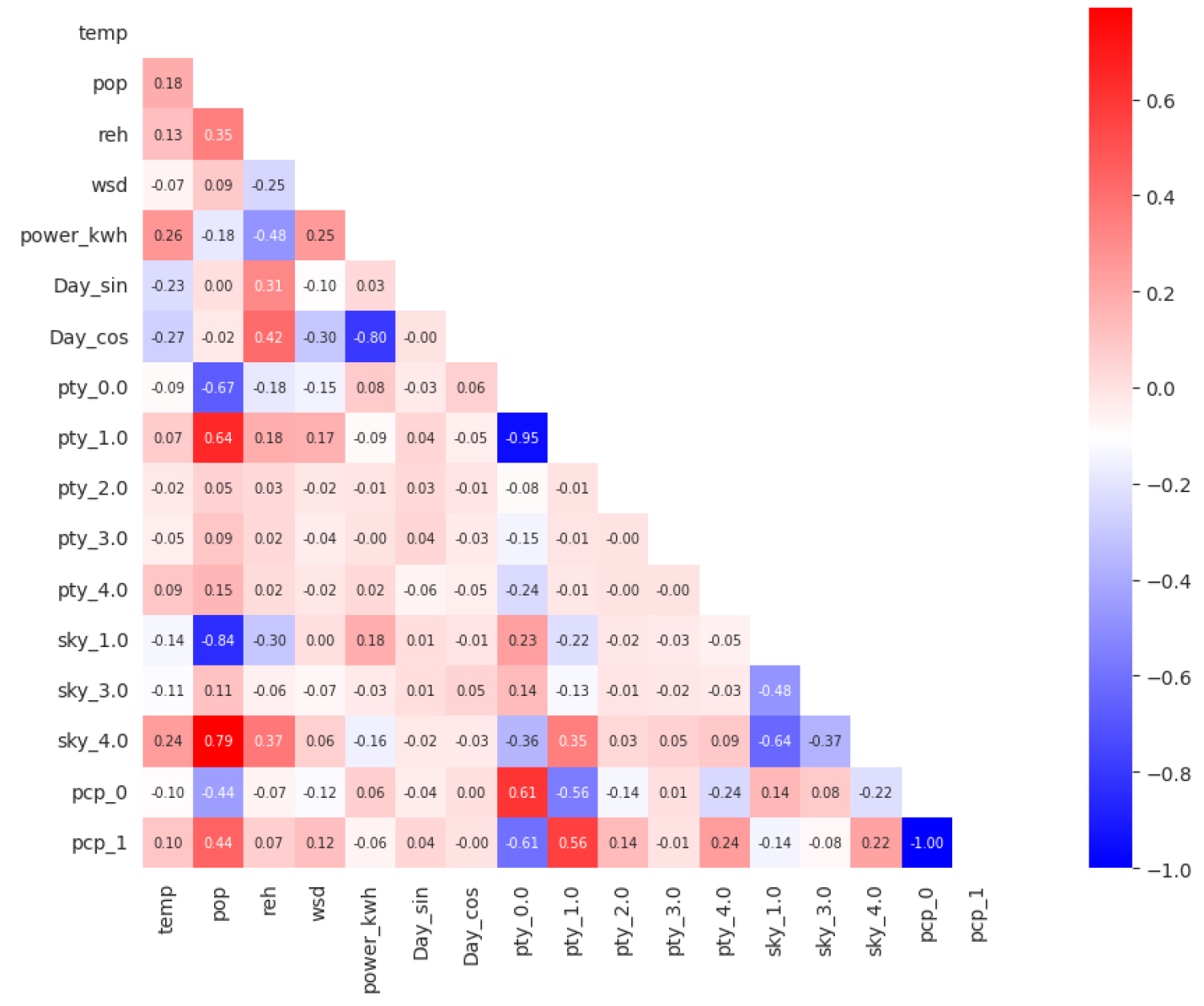
최종적으로 태양광 발전량과 기상 데이터의 상관도 분석을 하였을 때 상관도는 아래의 Fig. 2와 같다. 발전량과 상관관계가 높은 것은 시간, 습도 외 나머지는 크게 영향을 받지 않는 것으로 보인다.
2.2 예측 모델
(1) 앙상블 LSTM 모델
예측에 사용되는 모델은 LSTM 모델을 사용하였다. 학습에 사용되는 데이터는 모두 예측 해야 하는 시간대 보다 이전에 모두 얻을 수 있어서 다단계 예측이 아닌 단일예측으로 진행하였다. 예를 들어 예보 데이터를 14:00에 받는다면 예보 데이터만을 사용하여 내일의 태양광 발전량을 1시간씩 24번 예측을 진행한다.
앙상블 모델은 한 개의 모델을 예측하는 것보다 여러개의 모델이 같이 학습하여 더 높은 일반화된 정확도를 주며 한 개의 모델이 기상 오보로 인하여 크게 다를 경우 다른 모델의 예측값 평균으로 오차값을 보정 하여 준다.
∙LSTM 모델
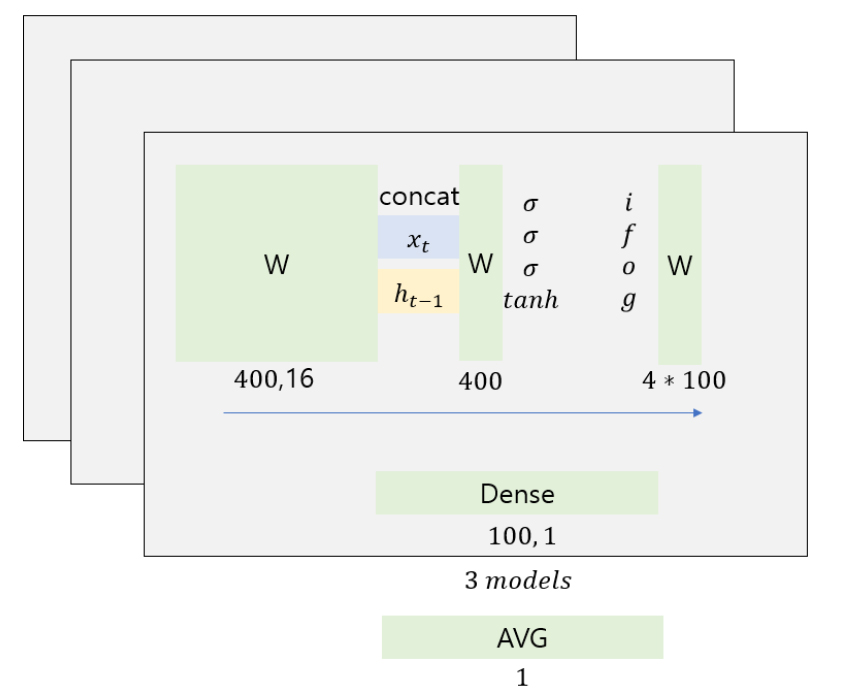
LSTM 모델은 시계열 분야에서 많이 사용되고 있다. 본 연구에 사용된 모델의 구조는 Fig. 3과 같다. 같은 LSTM 모델 3개를 집계함수 계층으로 결합하였다. feature는 16개이고 LSTM 뉴런 수는 100개이다. Dense 계층에서 LSTM 모델 결괏값이 나오며 LSTM 3개의 결괏값을 평균한 값이 최종값이다.
∙앙상블 모델
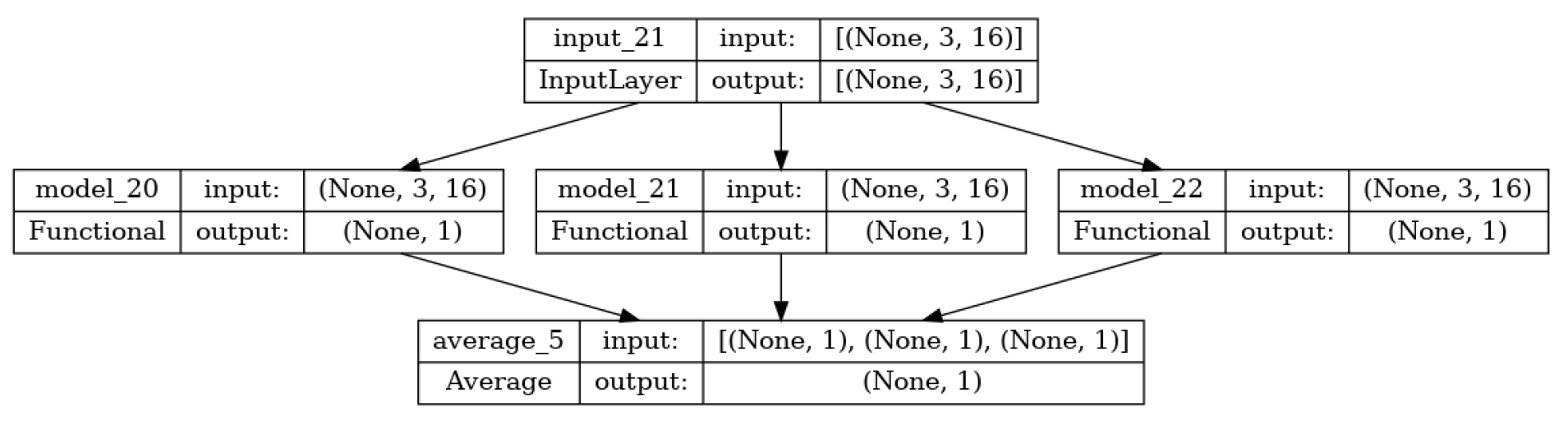
Fig. 4은 3개의 LSTM 모델이 평균으로 하기 위하여 Output Layer에 Average Layer를 추가하여 최종 출력한다. 각 모델을 학습시켜서 결과물을 집계하는 방법으로 Bagging을 사용한다.
∙하이퍼 파라미터
Table 2는 LSTM 모델에 사용된 하이퍼 파라미터이다. 데이터 분할은 교차검증 데이터 개수와 적합하도록 60일에 따른 훈련, 검증, 시험 데이터를 나누었다. 예측시장에 참여 하기위해서는 시험 일수가 30일 필요하기 때문에 시험 데이터를 최대한 30일로 만들었다. 조기종료 파라미터를 추가하여 과적합이 되는 것을 방지하였다. 배치 크기는 16 ~ 32 구간에서 학습이 되었고 그 중간인 24로 설정하였다. 학습 횟수는 100으로 설정하였다. 현재 데이터에서 100 이상 학습되는 횟수는 과적합이거나 불필요하다 판단하였기 때문이다. 활성함수는 보통 tanh를 사용하지만 현 데이터에서는 relu에서 더 높은 정확도를 보였다. 손실함수는 기상오보에 대한 큰 기울기 변동을 최소화하기 위하여 mae를 사용했다. 최적화함수는 기본함수인 adam을 사용하였다. 학습 뉴런 수는 feature수와 같은 16으로 시작하였으나 학습이 되지 않아 늘려 나갔으며 64 ~ 128 사이에서 학습이 되는 것을 확인하고 100으로 설정하였다. LSTM에 사용된 데이터 윈도우 개수는 3일 때 학습이 잘 되었고 이 보다 더 클 경우 학습이 되지 않았다.
Table 2
Model hyperparameters
(2) 교차 검증
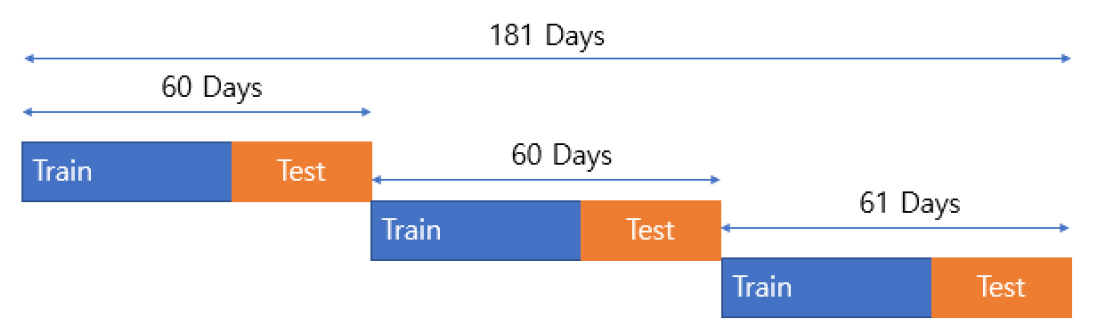
객관적인 정확도를 위하여 교차 검증을 진행하였다. 교차 검증 전략은 Fig. 5과 같다. 태양광 예측은 일기예보에 민감하여서 비교적 이상기후로 인하여 사계절 내 예측하는 것이 중요하다. 본 교차 검증은 3개로 나누어진다. 전체 데이터 181일 중에서 60일, 60일, 61일 총 3개로 나누었으며 60일 중에서 10일은 시험데이터 5일은 검증 데이터 나머지 55일은 훈련 데이터이다. 마지막 61일 데이터 세트에서는 61일 중에서 11일 시험데이터이며 나머지는 같다.
(3) 정확도 식
전력거래 시장에 참가하기 위하여 1달 동안 예측 정확도가 90% 이상이 되어야 한다. 전력거래 시장 참여를 위한 정확도 식은 식(3)과 같다. 또한 NMAE가 높을수록 정산받게 되는 비율이 높은지 확인하기 위하여 R의 식(7)도 계산한다. NMAE는 실제 발전량이 총 설비용량의 10%이상 되어야 해당 정확도 식에 포함된다. 따라서 해가 뜨지않는 시간은 정확도 산출식에 포함되지 않는다. 식(4)는 kWh당 3원의 발전량, 식(5)sms kWh당 4원의 발전량이다. 식(6)은 예측에 따른 전체 정산금이며, 식(7)은 예측 정산금에서 실제 발전량에서 kWh당 4원을 곱한 최대치로 받을 수 있는 정산금을 나눈것이다.
3. 결과 및 개선점
3.1 예측 결과
LSTM 모델과 비교하기 위하여 XGBM, LGBM 모델을 사용하였다. 비교대상 모델의 하이퍼 파라미터는 라이브러리에서 제공하는 기본 하이퍼 파라미터로 적용하였고 모델별 NMAE을 비교 하였다(Table 3).
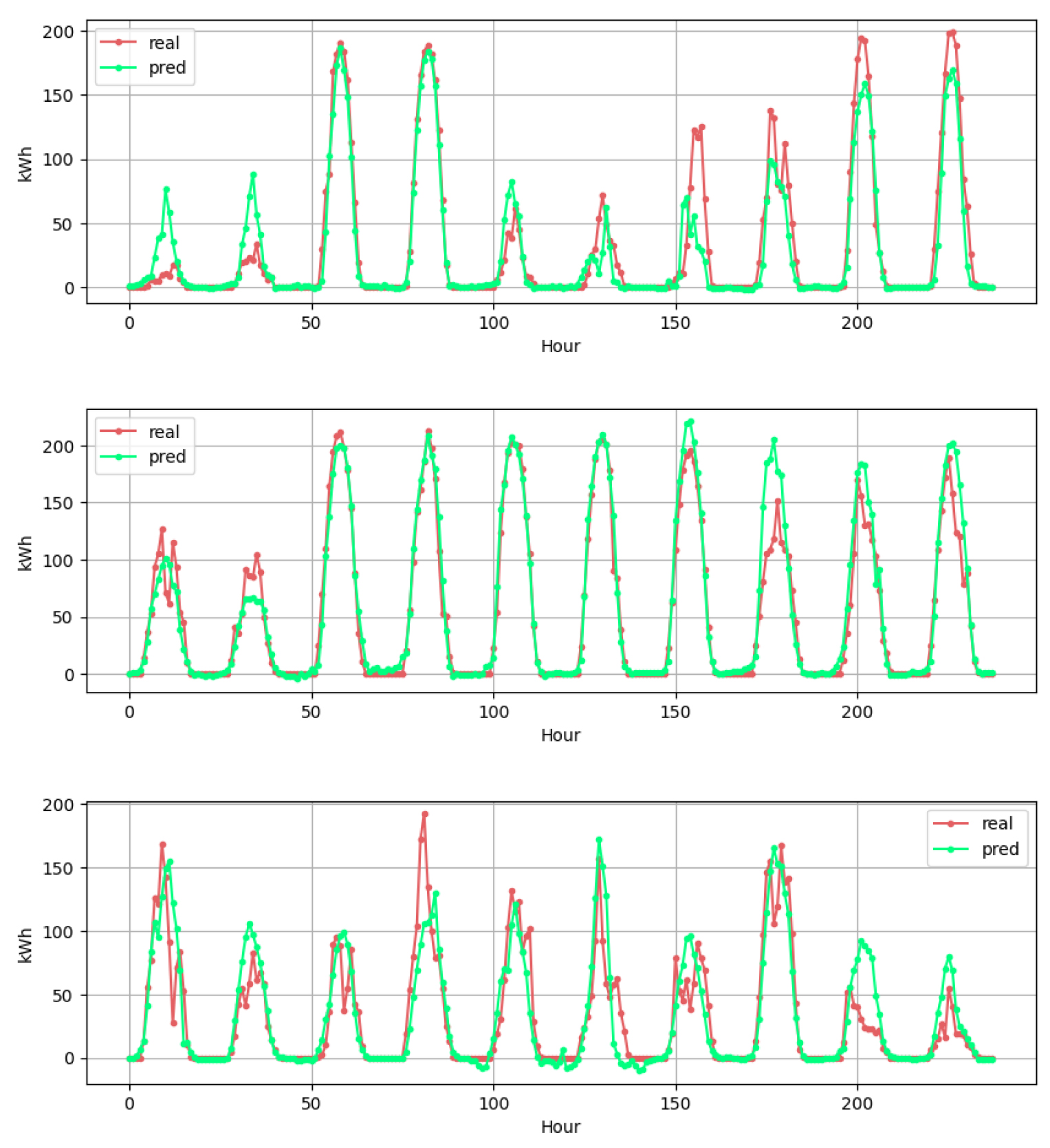
Table 4는 모델별 정산금 수령 비율이다. 정확도가 수준에 도달하여도 정산받을 수 있는 비중이 적으며 기업 입장에서는 정산금 수령 비율을 확인을 할 필요가 있다. Fig. 6은 최종 모델 LSTM의 발전량 예측 그래프이다.
Table 3
Cross-validation results (NMAE)
Table 4
Cross-validation results (Reward)
3.2 개선점
정확도가 90%에 근사하여 예측 인센티브를 받기 위해서는 더 높은 정확도가 필요하다. 한국 기상청에서 제공하는 데이터 외 다른 데이터를 추가하여 정확도를 높일 수 있다. 우리나라는 지역별 계절별 편차가 있기 때문에 각 지역별로 모델을 개발하거나 계절별로 모델을 개발하여야 한다. 또한 설비용량을 증가시켜 정확도를 올리는 방법이 있다.
(1) Global Forecast System (GFS), THREDDS 데이터 서버(TDS)
TDS는 과학 데이터 세트에 대한 메타데이터 및 데이터 액세스를 제공한다. 데이터 세트는 원격 데이터 액세스 프로토콜을 통해 제공 된다5). THREDDS 서버에 한국 기상청도 자체 노드를 구축하여 운영하고 있다6).
해당 사이트에서 제공하는 데이터 종류가 다양하여 미국 해양 기상청(NOAA)에서 운영하는 GFS에서 태양광 예측에 필요한 데이터 운량, GHI가 포함된 데이터를 추출하였다. 해당 데이터는 과거 30일 이상의 데이터를 제공하지 않기 때문에 사전에 데이터베이스 서버를 구축하여 데이터를 저장하는 것을 권장한다.
주요 데이터는 저고도, 중고도, 고고도 구름, 하향 단파 복사, 지면 온도 등 구름에 관한 데이터가 많이 있고 한국 기상청은 1시간 단위로 예보를 하지만 해당 데이터는 UTC 기준으로 00:00, 04:30, 06:30, 10:30, 12:00, 16:30, 18:00, 22:30 단위로 최장 7일까지 예보한다.
종관기상관측(ASOS)데이터와 GFS 데이터의 상관성을 비교하여 보면 Fig. 7에서와 같이 ASOS에서 관측된 일사,일조,전운량 데이터와 NOAA에서 예보한 GHI, 전운량 데이터가 강한 상관관계를 가지고 있다.
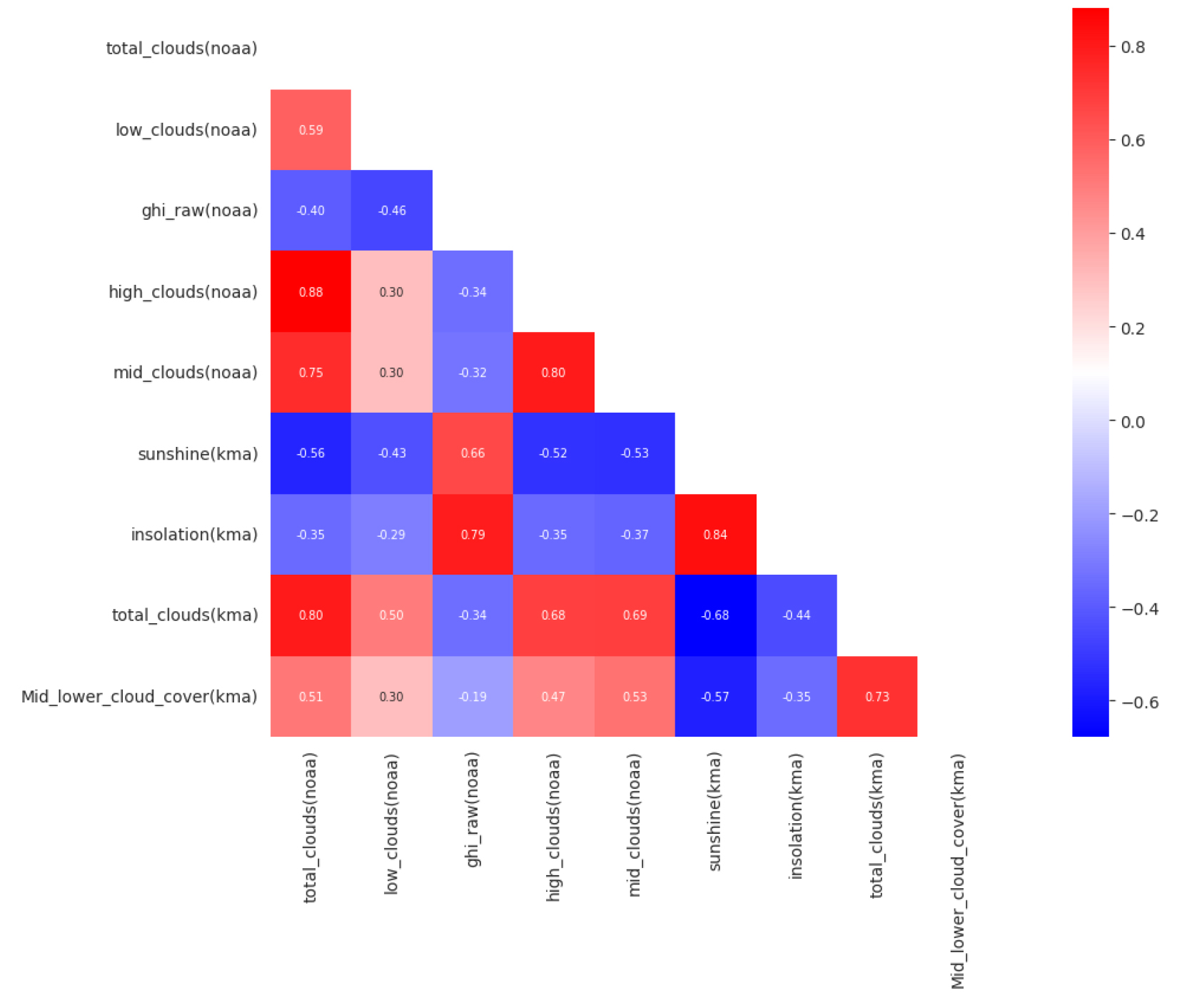
Table 5는 수집된 GFS 데이터와 ASOS데이터 표이다.
Table 5
GFS and ASOS data table
(2) 지역별 계절별 발전량 편차
남한의 지역별 일사량에 대한 발전량편차를 Gompertz model로 표현하게되면 지역별로 일사량에 비해 발전량 편차가 있다7). 또한, 계절별로 여름철 겨울철 발전량 편차가 있다7). 이에 따른 방안으로 발전량 예측 모델 생성시 지역별 계절별로 모델을 개발하는 방법이 있다.
(3) 설비용량의 증가
신재생에너지 예측시장 정확도 식은 총 설비용량에서 정규화시키기 때문에 설비용량이 클수록 정확도 식에 유리하다. 따라서 집합 자원을 최대한 많이 확보하여 최대한 모델을 일반화시켜야 하고 발전효율이 떨어지는 노후 태양광 자원을 확보하여 총 설비용량을 확보 하여야 한다. 노후 태양광과 겨울철 태양광 발전량은 설비용량보다 태양광 발전량이 적으므로 예측 정확도는 상승한다. 이러한 문제는 차후에 개선될 여지가 있어 보인다.
기업들은 이미 설비용량 확보를 위해서 태양광 사업을 영위하는 고객들에게 정산 수수료 수익을 전액 지급하는 방법과 태양광 자산관리와 같은 추가 플랫폼 서비스를 제공하거나 예측에 실패하더라도 태양광 예측 정산금을 지급하는 서비스를 제공하고 있다. 설비용량이 증가하면 기상예보가 틀리더라도 다른 자원에서 부족한 정확도를 보충해 줄 수 있으며 설비용량이 계속 증가할수록 국소적인 지역보다 지역 범위를 예측하기 때문에 예측난이도는 낮아 질 것으로 생각된다.
4. 결 론
신재생에너지 예측시장에 참가하기 위하여 공공 데이터만을 사용하여 정확도 90%에 도달에 초점을 맞추었다. 더 객관적인 정확도를 위하여 교차 검증을 하였고 여러 모델의 평균을 사용한 앙상블 방법을 사용하였다. 결과는 90.3%로 예측시장 참여에 적합한 정확도이다. 정확도가 아슬하게 나온 이유는 여름철 이상기후가 7월에 집중되어 있어 테스트 셋이 이상기후(태풍) 기간에 배치되어 있었다. 한 기관의 기상예보 데이터만으로는 예보를 맞추기 어려우므로 외부 기상 데이터를 적절하게 활용하여 기존 앙상블 모델에 추가할 수 있다.
정확도와 예측 정산금은 크게 비례하지 않으며 꼭 정확도와 정산금을 받을 수 있는 비율을 확인하는 것이 중요하다. 정산금을 최대한 받기 위해서는 정확도 94% 이상이 필요하며 정확도를 개선하는 방법으로 모델 개선이 필요하다. 모델을 개선 시키는 방안으로 데이터베이스를 구축하여 NOAA에서 제공하는 GFS 외부 기상 예보 데이터 수집하여 사용하거나 설비용량을 확보하여 모델을 일반화 시키거나 발전효율이 비교적 낮은 태양광 설비를 자원에 확보하는 방법이 있다. 또한 우리나라는 지역별, 계절별 발전량 편차가 있기 때문에 지역별, 계절별 모델을 개발하는 방법이 있다. 이 와 같은 방법으로 설비 효율이 낮은 겨울철에 예측제도에 참여해 정확도를 높이는 방법이 있다.
앞으로는 더 많은 기관과 기업들이 재생에너지 지원 정책에 따라 재생에너지 중개 거래에 참여할 것으로 보이면서 모델 개선과 설비용량 확보에 박차를 가할 것으로 생각된다.
