

1. 서 론
2. 연구방법
2.1 인공신경망 모델 구현을 위한 학습 자료 항목 선정 및 생성
2.2 하이퍼파라미터 조정을 통한 성능 예측 인공신경망 모델의 최적화
2.3 최대출력점 예측 모델의 검증
3. 최대출력점 예측 모델 개발 및 검증
3.1 최대출력점 예측 모델의 최적화
3.2 최대출력점 예측 모델의 검증
4. 결 론
기호설명
: DC Power (W)
: DC Current (A)
: DC Voltage (V)
: Ratio of DC Power (-)
: Ratio of DC Current (-)
: Ratio of DC Voltage (-)
: Predicted Ratio of DC Power (-)
: Predicted Ratio of DC Current (-)
: Predicted Ratio of DC Voltage (-)
: Measured Ratio of DC Power (-)
: Measured Ratio of DC Current (-)
: Measured Ratio of DC Voltage (-)
1. 서 론
대한민국 정부는 2030년까지 재생에너지 발전량 비중을 20%로 늘리는 것을 목표로 하고 있으며, 이를 위해 산업통상자원부는 2017년 12월 ‘재생에너지 3020 이행계획(안)’을 발표하였다. 이행계획(안)을 보면 다양한 재생에너지 중 태양광발전시스템과 풍력발전시스템을 통해 신규설비의 약 97%를 보급하는 것을 목표로 하고 있으며, ‘주택·건물 등 자가용’, ‘협동조합 등 소규모 사업’, ‘농가 태양광’, ‘대규모 프로젝트’로 세분화하여 달성 계획을 수립하였다. 이중 ‘주택·건물 등 자가용’은 보급사업 확대 및 제로 에너지건축물 인증 의무화 등을 통해 국민 참여를 유도하고 있다1). 이외에도 공공건축물 신 재생설비설치 의무화 제도, 건축물 에너지효율등급 인증제도 등이 있으며, 각 지역의 ‘녹색건축물 설계기준’1을 통해 민간건축물에도 태양광발전시스템을 포함한 신재생에너지 시스템을 설치하도록 하고 있다.
다양한 신재생에너지 시스템 종류 중 건축에 적용되는 신·재생에너지 시스템 유형은 태양광발전시스템(PV, Photovoltaic System), 태양열(Solar Thermal), 연료전지(Fuel Cell), 지열 등이 있다. 보통 옥상에 설치되는 건물부착형 태양광발전시스템(BAPV, Building Attached PV System)이 주로 설치되며2,3,4,5,6), 제한적인 면적이나 주변 환경 영향으로 인해 충분한 설치가 어려운 경우 건물일체형 태양광발전시스템(BIPV, Building Integrated Photovoltaic), 지열, 연료전지 등이 설치되고 있다.
신재생에너지 시스템이 적용된 공공기관의 사용자나 시설담당자를 대상으로 설문조사 연구를 수행한 선행 연구7)에 따르면, 조사대상의 37.5%는 시스템 운영 중 고장 발생 여부조차 파악하고 있지 못하고 있는 것으로 나타났다. 동일 연구의 결과 중 신재생에너지 시스템의 만족도에 부정적인 영향을 미치는 요인 중 하나인 ‘유지관리의 기술적 어려움’, 모니터링 시스템에 요구하는 기능 중 하나인 ‘고장진단 자동화’보면 시스템 관리자나 사용자가 신재생에너지 시스템의 유지관리에 대한 어려움이 있는 것을 알 수 있다.
이러한 관리자나 사용자의 어려움을 해소하기 위해 태양광발전시스템에 대한 다양한 고장진단 및 세분화 기술이 개발되고 있다. 다양한 진단 기술 중 ‘전압 전류 측정 방식’의 경우 어레이 출력과 어레이 전압, 전류를 활용하여 고장진단 기술로 노출된 조건(일사량, 외기온도 등)에서 최대출력점(출력, 전류, 전압)을 예측하며 이 값을 임계값으로 활용하여 실측값과 비교를 통해 고장진단을 수행한다8,9,10,11). 이 때 노출된 조건에서 최대출력점 예측을 위해 One-Diode Model을 활용한다. 하지만 One-Diode Model은 결정계 태양광 모듈에 대한 예측을 매우 정확하지만, 결정계를 제외한 다른 유형의 모듈에 대해서는 예측성능이 다소 낮은 것으로 나타난다12). 이러한 한계를 극복하기 위해서는 다양한 모듈이 적용되더라도 효과적으로 최대출력점을 예측할 수 있는 새로운 방법이 필요하며, 이는 기계학습을 통한 예측 모델 생성을 통해 가능할 것으로 판단된다.
따라서, 본 연구는 고장진단 및 성능저하 요인 검출 목적의 인공신경망 기반 최대출력점 예측 모델 최적화 및 국내 BAPV 시스템의 모니터링 자료를 활용한 검증을 통해 유지관리를 위한 인공신경망 기반 최대출력점 예측 모델을 개발하고자 하였다.
2. 연구방법
건물적용 태양광발전시스템을 포함한 모든 태양광발전시스템은 구성 하드웨어의 파손이나 고장 등 외에도 표면오염 등 외부요인에 의한 성능저하 요인이 존재한다. 고장이나 성능저하 요인이 발생했을 때, 정확한 진단 및 유지관리가 이루어지면 시스템은 설계 성능과 유사하게 운영될 수 있으며, 유지관리 없이 운영되었을 때에 비해 획득할 수 있는 에너지는 증가하게 된다.
태양광발전시스템의 고장진단 및 성능저하 요인의 발생 여부 판단을 위해서는 노출된 외기 조건에서 정상적인 출력에 대한 예측이 필요하다. 또한 고장 및 성능저하 요인의 세분화를 위해서는 정상 출력에 대한 전압 및 전류의 예측이 필요하다. 결정계 태양전지를 활용하여 제작된 모듈의 경우 One-Diode Model을 통해 정상적인 출력, 전압 및 전류에 대한 예측이 가능하지만, 본 연구에서는 다양한 유형의 태양광발전 모듈에 대한 정상적인 출력 예측을 위해 인공신경망을 활용하였다. 인공신경망을 활용한 성능 예측 모델은 하이퍼파라미터(Hyperparameter)에 대한 최적화 수행을 통해 구현되었으며, 국내 건물부착형 태양광발전시스템(BAPV, Building Attached PV System)의 모니터링 자료를 활용하여 검증되었다. 본 연구는 Fig. 1의 과정을 통해 수행되었으며, 인공신경망을 활용한 성능 모델의 최적화 방법 및 국내 BAPV 시스템의 모니터링 자료를 활용한 검증 방법은 다음과 같다.
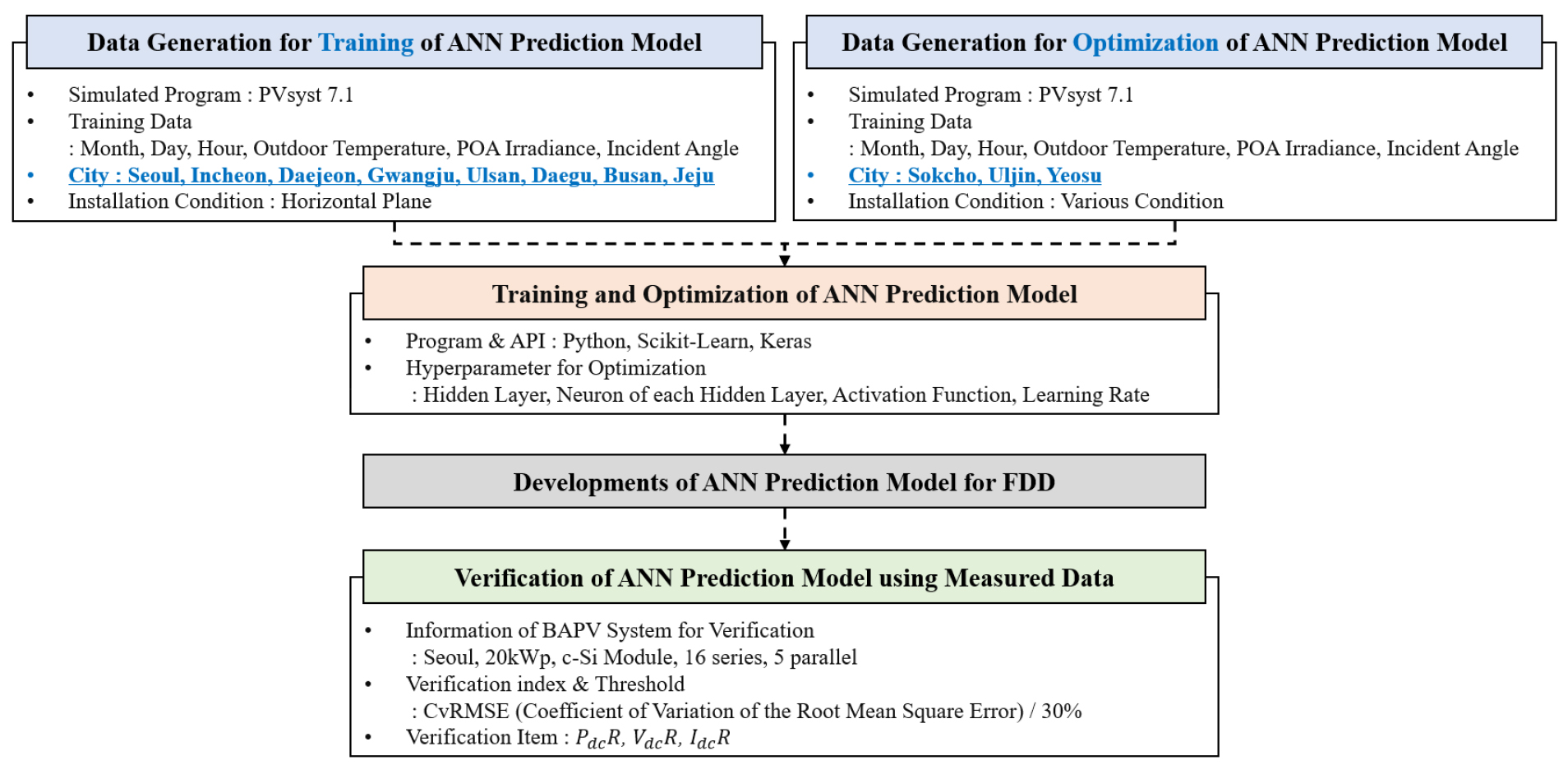
2.1 인공신경망 모델 구현을 위한 학습 자료 항목 선정 및 생성
앞서 언급한 것처럼 태양광발전시스템은 외기온도 및 일사량 등 노출된 외기 조건에 의해 어레이 출력()과 어레이 전압(), 어레이 전류()가 결정된다. 시스템의 고장이나 성능저하 요인이 발생했을 때 , 감소가 발생하며 최종적으로 감소로 이어진다. 따라서, , , 는 태양광발전시스템의 정상 동작 여부 및 진단을 위한 기초자료로 주로 활용된다8,9,10,11). 하지만 , , 는 시스템 규모 및 어레이 내 모듈의 직렬·병렬 설계에 따라 다양한 값을 나타내기 때문에 성능 예측 모델을 범용적으로 활용하기 위한 방법이 필요하다. 따라서, 본 연구에서는 , , 와 시스템 설계 정보 중 용량(), 어레이 최대출력점 전압(), 어레이 최대출력점 전류()를 활용하여 , , 를 일반화하였다. , , 의 일반화는 아래 식을 통해 수행되었으며, 그 값은 , , 로 표기하였다. 이때 어레이 최대출력점 전압과 전류는 모듈의 사양과 어레이 구성정보를(직렬, 병렬 연결 정보) 활용하여 산출한 값을 의미한다.
인공신경망 모델을 통해 , 을 직접 예측하였으며, 을 예측된 , 을 활용하여 산출하였다. , 의 예측을 위한 입력 항목은 시간에 대한 정보를 나타내는 월, 일, 시를 활용하였으며, 태양광발전시스템의 성능에 직접적인 영향을 미치는 외기온도와 일사량, 입사각을 포함하여 인공신경망 모델의 학습을 수행하였다. 이때 일사량은 어레이와 동일한 설치 조건(방위각 및 경사각)의 값을 활용하였다. 인공신경망 모델의 학습을 위해 활용된 자료는 Table 1과 같다.
Table 1.
The information of data for training and test to ANN model
| Input Data | Output data (Predicted data) |
| Month, Day, Hour, Outdoor Temperature, POA Irradiance, Incident Angle | , |
Table 1의 각 항목에 대한 데이터는 PVsyst 7.1을 활용한 해석을 통해 생성하였다. 학습 데이터 생성을 위한 해석 모델 정보는 Table 2, Table 3와 같다. 국내 11개 지역에 대해 해석한 결과를 활용하였으며, 8개 지역은 인공신경망 모델의 학습, 3개 지역은 최적화를 위한 하이퍼파라미터 조정에 따른 각 모델의 예측 성능 평가를 위해 활용되었다. 학습을 위한 8개 지역의 경우 설치조건을 모두 수평면으로 모델링하여 해석하였으며, 각 모델의 예측 성능 평가를 위한 3개 지역의 경우 설치조건을 다양하게 변화하여 해석하였다. 이는 수평면 설치조건으로 해석된 값을 활용하여 학습된 예측 모델이 다양한 설치조건에 대한 예측이 가능한지 평가하기 위함이다.
Table 2.
The location and installation condition of simulation model for data generation
Table 3는 해석 모델에 적용된 모듈의 제원, 어레이 사양을 나타낸 것이다. 결정계 유형의 300 Wp 모듈 11장을 직렬 연결하여 모델을 구성하였으며, 총 3.3 kWp의 설치용량을 갖도록 구성하였다. 어레이 사양 중 Nominal power, Voltage of maximum power point, Current of maximum power point의 값이 각각 , , 을 산출하는데 활용된다. 이 외에도 시스템의 성능에 영향을 미치는 후면환기조건, 표면오염, 입사각 영향 등의 모델링 요소는 PVsyst 7.1에서 제공하는 기본값을 변경하지 않고 해석하였다. 해석 모델과 ASHRAE IWEC 2 표준기상자료를 활용하여 11개 지역에 대한 시간별 , , , 외기온도, 일사량, 입사각을 분석하였으며, 앞서 언급한 Nominal power, Voltage of maximum power point, Current of maximum power point를 활용하여 , , 를 산출하였다. 위 과정을 통해 최종적으로 학습 및 하이퍼파라미터 조정에 따른 각 모델의 성능 평가를 위한 Table 1의 자료 생성하였다.
Table 3.
The specification about PV module and array of simulation model for data generation
2.2 하이퍼파라미터 조정을 통한 성능 예측 인공신경망 모델의 최적화
인공신경망 모델이 최적의 예측성능을 갖도록 하기 위해서는 인공신경망 구조 및 학습률 등 하이퍼파라미터에 대한 최적화가 필요하다. Fig. 2는 인공신경망의 구조 및 학습 과정을 나타낸 것이다. 인공신경망의 구조는 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer), 활성화함수(Activation Function), 가중치(Weighting Factor)로 구성된다. 각 층은 뉴런(Neuron)은 독립적이며 다음 층의 각 뉴런과 가중치로 연결되어 있다. 첫 번째 학습 데이터 세트2(예 : 1월 1일 00시의 학습데이터)가 입력되면 입력층 값과 출력층의 정답(Label)이 결정된다.
Fig. 2의 우측 그림처럼 첫 번째 은닉층()의 각 뉴런의 값은 입력층의 각 뉴런의 값과 첫 번째 은닉층()의 각 뉴런과 연결된 가중치 및 활성화함수를 통해 값이 결정된다. 동일 과정을 통해 두 번째 은닉층()의 각 뉴런에 대한 값이 결정되며, 다시 동일 과정을 통해 출력층의 각 뉴런에 대한 값이 결정된다. 이 과정을 거쳐 예측된 출력층의 값은 학습 데이터 세트의 출력층 정답(Label)과 비교를 통해 각 가중치의 보정을 수행한다. 이때 보정은 크기는 학습률(Learning Rate)에 따라 결정된다. 전체 학습 데이터의 반복 학습(Epoch)를 통해 가중치의 보정이 수행되며, 결과적으로 학습과정을 통해 뉴런을 연결하는 가중치가 결정되게 된다.
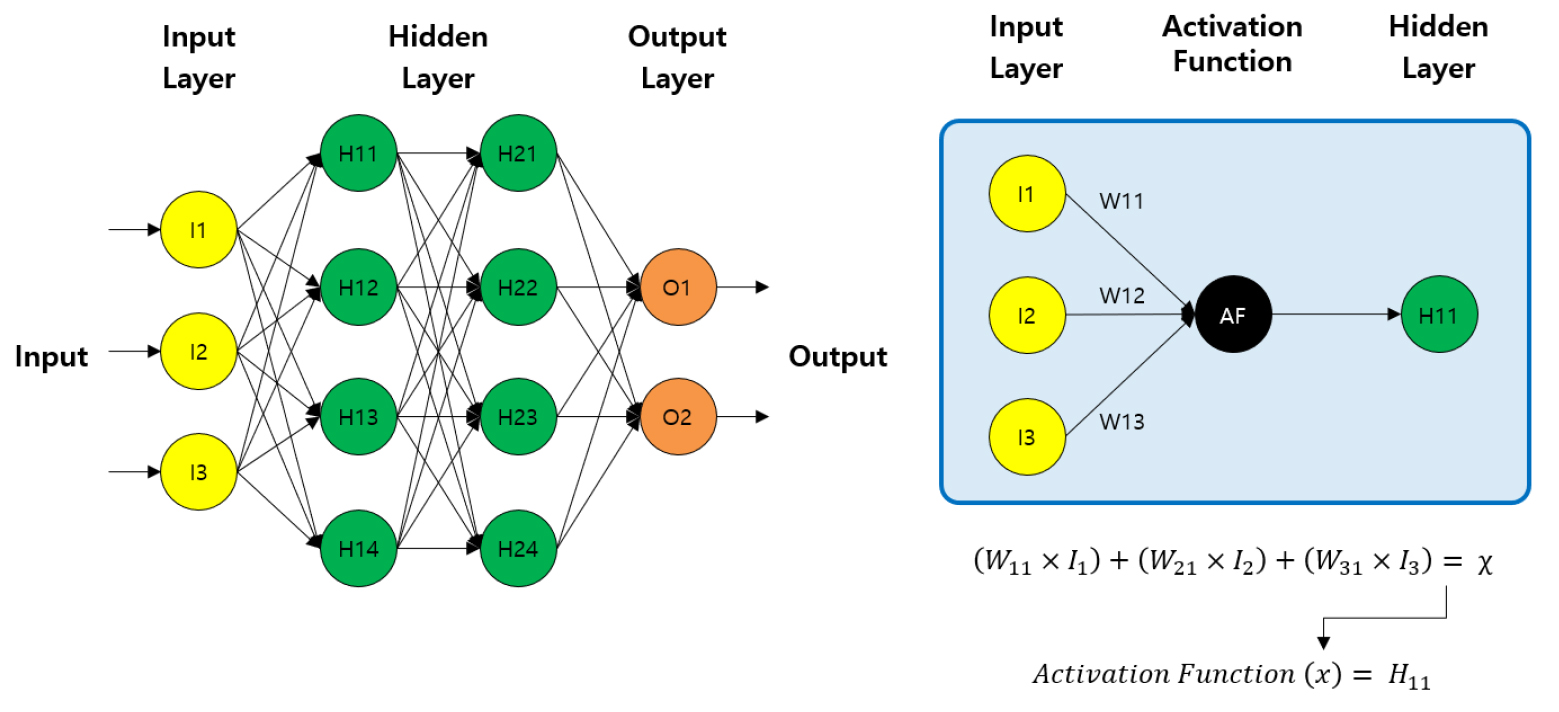
앞서 설명한 인공신경망 모델의 학습 과정을 보면 결국 은닉층의 개수, 은닉층 내 뉴런의 개수, 각 층의 활성화함수, 학습률에 따라 예측 모델의 성능이 결정됨을 알 수 있으며, 실제로도 성능에 영향을 미치는 것으로 나타난다. 따라서, 본 연구에서도 앞서 언급한 4개지 항목의 조정을 통해 예측 모델의 최적화를 수행하였으며, 최적화 연구 수행을 위해 각 항목의 변수는 Table 4와 같이 선정하여 최적화 연구를 수행하였다. 각 최적화 변수의 조합에 따른 모델을 도출하였으며, 각 모델을 활용하여 예측한 값과 PVsyst 7.1을 통해 해석된 값의 비교를 통해 예측성능이 가장 우수한 모델 1개를 최적 성능 모델로 선정하였다. 예측값과 해석된 값의 비교는 Table 2의 ‘Test Data’에 속하는 조건과 결과를 활용하였으며, CvRMSE (Coefficient of Variation of the Root Mean Square Error)를 활용하여 평가하였다. 각 인공신경망 모델의 구축 및 최적화 연구를 위해 Python, Scikit-Learn, Keras를 활용하였다.
Table 4.
The variable of each hyperparameter for optimization of ANN model
2.3 최대출력점 예측 모델의 검증
최적화 연구 결과로 도출된 최대출력점 예측 모델의 검증을 수행하였다. 국내에 위치한 BAPV 시스템을 활용하였으며, 최적화 연구에서 활용된 CvRMSE를 검증 지표로 활용하였다. ASHRAE Guideline 1413)에 따르면 시간간격 데이터를 활용한 검증에서 CvRMSE가 30% 이하인 경우 예측 모델이 실제 현상을 잘 모사하는 것으로 판단한다. 따라서, 본 연구에서도 CvRMSE 30%를 기준으로 최대출력점 예측 모델의 검증을 수행하였다.
검증에 활용한 BAPV 시스템은 서울에 위치하고 있으며, 건물의 옥상에 지지구조물을 설치한 후 모듈을 거치해놓은 형태로 일반 태양광발전시스템과 유사한 형태로 설치되었다. 어레이는 250Wp 결정계 태양광 모듈 80장을 16직렬, 5병렬로 구성하여 총 20 kWp의 설치용량을 갖는다. 어레이 설치 방위각 및 경사각은 각각 142.5°, 30°로 구성되어 있으며, 모듈 및 어레이의 상세 제원은 Table 5와 같다. 검증을 위한 BAPV 시스템의 모니터링 자료를 2013년 2월 1일부터 2015년 8월 10일까지의 모니터링 자료를 활용하였으며, 모니터링 시스템의 오작동으로 인한 결측 일을 제외하면 총 790일 동안 측정된 자료가 검증에 활용되었다. 정상 성능 예측을 위한 외기온도 및 일사량 또한 동일 모니터링 시스템에서 측정된 자료를 활용하였으며, 입사각의 경우 BAPV시스템의 위도, 경도, 방위각, 경사각을 활용하여 산출된 값을 활용하였다.
Table 5.
The specification about PV module and array of BAPV system for verification
3. 최대출력점 예측 모델 개발 및 검증
3.1 최대출력점 예측 모델의 최적화
Fig. 3는 하이퍼파라미터의 조합(Table 4 참조)에 따른 각 모델의 예측성능을 나타낸 것이다. 각 모델의 학습은 Table 2의 Training Data를 통해 수행되었으며, 각 모델의 예측성능 평가는 Test Data를 통해 수행되었다. Fig. 3의 3개 그래프는 x축은 은닉층의 수로 고정하였으며, y축을 은닉층 내 뉴런수, 학습률, 활성화함수 변화했을 때 예측값과 해석값(PVsyst 7.1을 통한 해석결과)간의 CvRMSE를 z축에 나타낸 것이다.
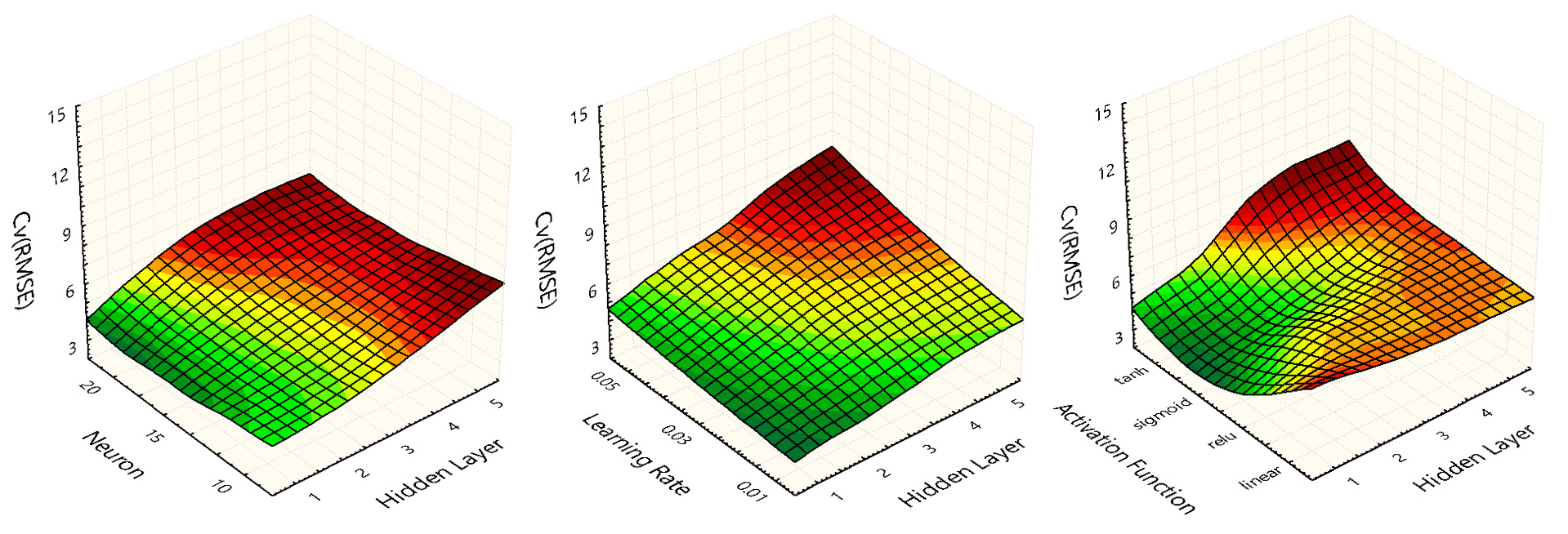
예측 모델의 성능은 은닉층의 수가 1개일 때 가장 높은 예측성능을 나타내는 것으로 나타냈으며, 학습률은 0.01일 때 가장 높은 예측성능을 나타냈다. 활성화함수는 Logistic Function에서 가장 높은 예측성능을 나타냈으며, 은닉층 내 뉴런은 20개 일 때 가장 높은 예측성능을 나타내는 것으로 나타났다. 최적화 연구 결과에 따른 인공신경망 모델의 구조 및 학습률, 활성화함수는 Table 6와 같다.
Table 6.
The hyperparameters of optimized ANN model
| Hidden Layer | Neuron | Learning Rate | Activation Function | CvRMSE [%] |
| 1 | 20 | 0.01 | Logistic Function | 3.14 |
3.2 최대출력점 예측 모델의 검증
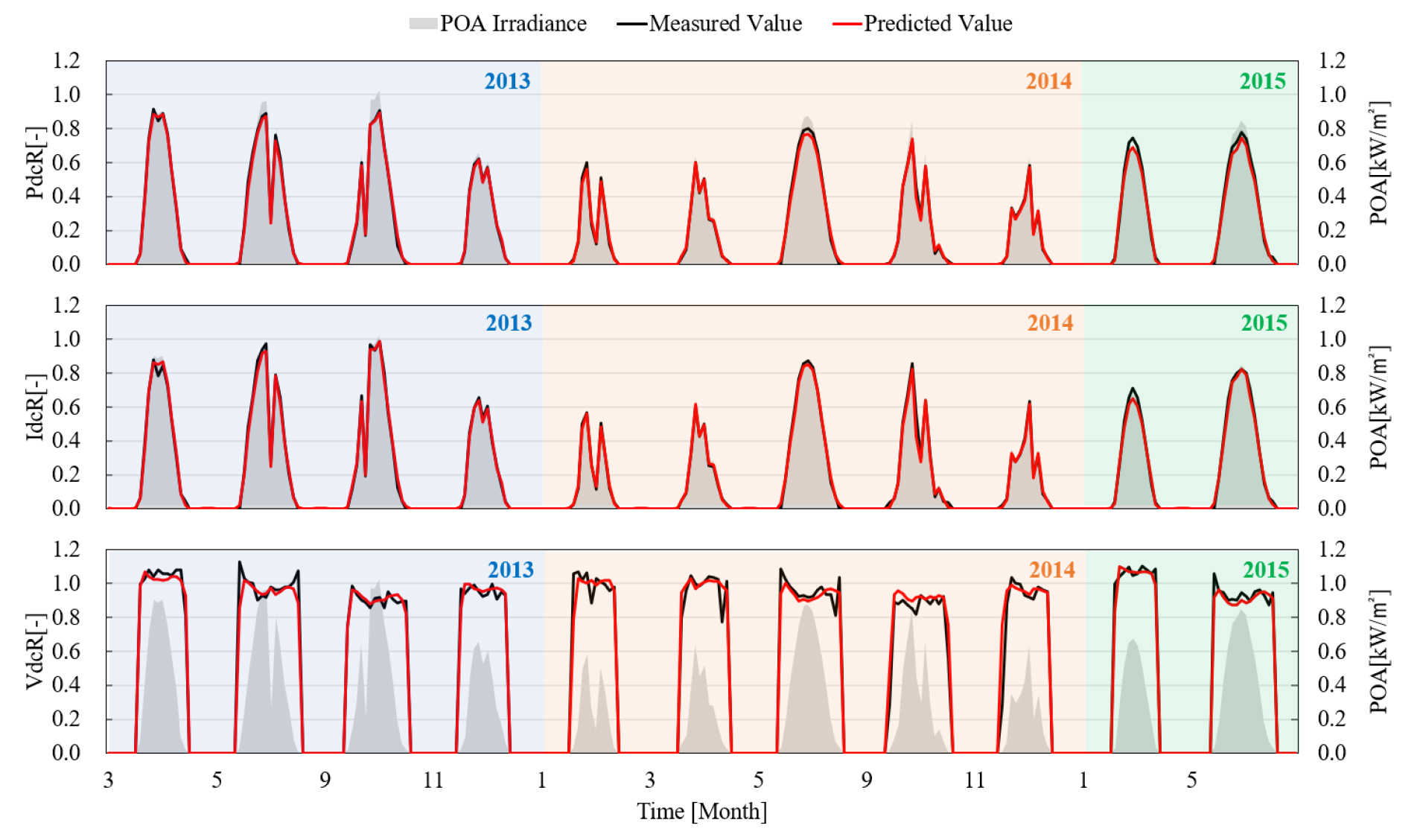
Fig. 4는 검증 대상 BAPV 시스템의 모니터링 자료와 설계 정보를 통해 산출된 , , 에 대한 최대출력점 예측 모델을 통해 예측된 , , 를 나타낸 것이다. 앞서 설명한 것처럼 는 , 를 통해 산출된 값이다.
Fig. 4의 , 에 대한 예측값과 실측값의 산점도의 추세선을 보면 모두 약 0.97을 나타내고 있어 측정값에 비해 예측값이 낮긴 하지만 비교적 양호한 예측성능을 나타내는 것으로 분석되었으며, 결정계수 또한 0.99 이상으로 각 데이터 포인트들이 추세선과 근접하게 분포되어 있는 것으로 분석되었다. 의 경우 산점도 상으로 봤을 때는 데이터 포인트들이 추세선을 중심으로 매우 산포되어 있는 것으로 보이지만, 결정계수 분석 결과 약 0.98로 양호한 수준을 나타냈다. 추세선의 기울기 또한 약 0.99로 우수한 예측성능을 나타냈다. Fig. 4의 데이터를 활용하여 실측값과 예측값의 CvRMSE 분석결과, , , 가 각각 11.66%, 11.70%, 18.01%로 분석되어, ASHRAE Guideline 1413)의 기준인 30% 이내로 분석되었다.
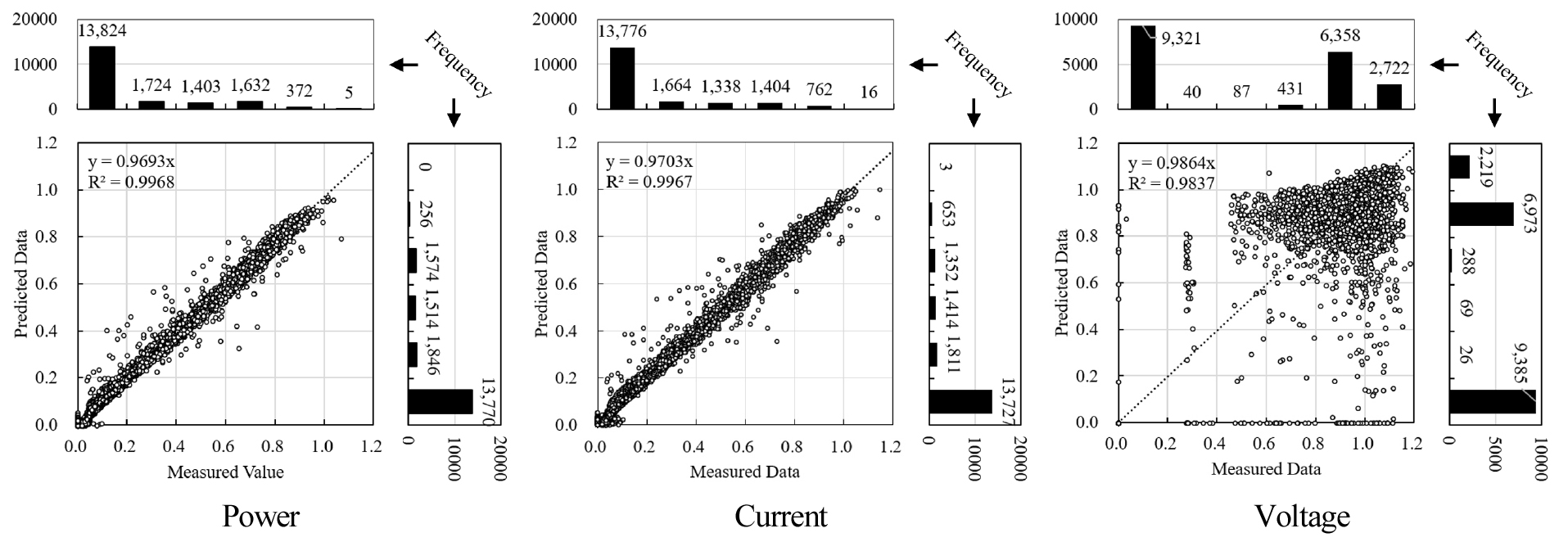
Fig. 5는 검증에 활용된 모니터링 자료의 전체 기간 중 홀수 월의 1일에 대한 일사량, 측정값, 예측값을 나타낸 것이다. 가장 위의 그래프부터 , , 을 순서대로 나타낸 것이며, 누락된 2013년 7월 1일, 2014년 7월 1일, 2015년 3월 1일, 7월 1일의 경우 모니터링 시스템의 오작동으로 결측되었다. 인공신경망 기반의 예측 모델을 통해 직접 예측한 , 의 예측 성능을 분석하면, 일사량의 변화패턴에 맞춰 정확히 예측하는 것을 알 수 있으며, 일부 실측값에 비해 낮게 예측하는 구간이 발생하지만 그 차이는 크지 않은 것으로 분석되었다. 예측된 , 를 통해 산출된 또한 비교적 정확한 예측성능을 나타내는 것으로 분석되었다.
4. 결 론
본 연구에서는 태양광발전시스템의 고장진단 및 유지관리를 위한 인공신경망 기반의 최대출력점 예측 모델 개발 및 검증 연구를 수행하였다. 실측 모니터링 자료가 아닌 해석프로그램을 통해 생성된 자료를 활용하여 학습을 하였으며, 은닉층의 수, 은닉층 내 뉴런수, 활성화함수, 학습률 등 하이퍼파라미터 조정을 통한 최적화 연구를 수행하였다. 또한 최적화 연구를 통해 도출된 모델을 대상으로 실측 모니터링 자료를 활용한 검증을 수행함으로 최대출력점 예측 모델을 평가하였다.
(1) 최대출력점 예측 모델의 최적화 및 생성을 위한 학습 자료, 시험 자료는 PVsyst 7.1을 통해 생성된 해석 결과(해석값)를 활용하였다. 국내 11개 지역을 대상으로 학습 자료와 시험 자료를 생성하였으며, 학습 자료로 국내 주요 도시 8개 지역의 해석 결과를 활용하였고 시험 자료로 국내 3개 지역을 해석 결과를 활용하였다.
(2) 인공신경망 모델의 최적화를 위해 은닉층의 수, 은닉층 당 뉴런의 수, 학습률, 활성화함수를 조정하였으며, 이를 통해 은닉층의 수 1개, 은닉층 당 뉴런의 수 20개, 학습률 0.01, 활성화함수 Sigmoid Function로 구성된 인공신경망 모델이 최적 모델로 도출되었다. 이 모델의 예측성능은 해석값과 예측값 간의 CvRMSE가 3.14%로 분석되었다.
(3) 서울지역에 위치한 BAPV 시스템의 모니터링 자료를 활용하여 최대출력점 예측 모델의 검증을 수행하였으며, 전체 기간에 대한 실측값과 예측값의 CvRMSE 분석결과, , , 가 각각 11.66%, 11.70%, 18.01%로 분석되었다. 홀수 월 1일에 대한 분석결과, , 의 경우 일사량의 변화에 따라 정확히 예측하는 것으로 나타났으며, 또한 정확히 예측하는 것으로 분석되었다.
(4) 본 연구를 통해 개발된 인공신경망 기반의 모델은 태양광발전시스템의 고장진단 및 유지관리를 목적으로 활용 가능할 것으로 판단된다. 하지만 현재 단계의 연구 결과를 통한 고장진단은 고장진단의 발생 여부만을 판단할 뿐 고장 원인의 세분화된 진단은 불가능하다. 따라서, 향후 고장진단 자동화 및 고장진단 항목의 세분화를 위해 성능분석기법, 전류-전압 특성곡선 측정기법, 열화상 영상 진단기법 등 다양한 측정 및 진단 기술과 기계학습 기술이 혼합된 고장진단 기술의 개발 및 적용이 필요할 것으로 판단된다.
본 연구는 해석된 결과를 활용하여 최대출력점 예측 모델을 개발하고 이를 검증하였다. 향후 본 연구의 결과를 토대로 다양한 모듈의 측정 자료를 통한 모듈의 발전 특성이 반영된 최대출력점 예측 모델 개발이 가능할 것으로 판단되며, 후속 연구로 이를 수행할 예정이다.
