

1. 서 론
2. 연구 방법
2.1 분석대상 선정
2.2 투입 변수
3. 기계 학습 및 장기 추세 분석 결과
3.1 기계학습
3.2 데이터 셋 및 기계학습 모델 선정
3.3 기계학습의 결과
3.4 SMP의 장기 추세 예측 결과
4. 결 론
1. 서 론
최근 산업통상자원부에서는 2034년까지 총 60기의 석탄발전 중 30기를 폐지하고 30기 중 24기를 액화천연가스(Liquefied Natural Gas, LNG) 등 다른 연료원을 활용하는 발전으로 전환하고 신재생 에너지 설비용량을 77.8 GW까지 확대하는 계획1)을 발표하였다. 2020년 신재생 에너지 전체 설비용량이 약 20.1 GW임을 감안하면 2034년까지 57.7 GW의 설비용량이 증설되어야 하므로 목표 달성을 위해서는 신규 설비 투자에 대한 사전 경제성 분석이 신속하고 정확하게 이루어 져야 한다2,3). 경제성 분석에서 사용되는 계통한계가격(System Marginal Price, SMP)은 2010년부터 육지 SMP (Main land SMP)와 제주 SMP (Jeju SMP)로 분리되어 집계되고 있다. SMP의 변동성은 발전사업자의 수익에 직접적인 영향을 주기 때문에 SMP 전망치의 정확하고 신뢰성 있는 추정은 매우 중요하다.
정확하고 신뢰성 있는 SMP 추정을 위해서는 SMP 결정 요인 선정과 변동성 반영이 중요하다. SMP 결정 요인에는 LNG, 국제 유가 등 발전원별 가격과 환율, 기온, 계절 등이 있다. 가격 결정 요인들의 불규칙한 변동성은 정확하고 신뢰성 있는 SMP의 예측을 어렵게 하며 이를 해결하기 위하여 다양한 연구가 수행되고 있다. SMP 결정 요인 중 국제 유가, LNG 가격, 환율이 SMP와 연관성이 큰 것으로 선행연구4,5)를 통해 확인되었다. SMP 예측에는 전통적으로 시계열 분석 기법인 자기회귀누적이동평균(Autoregressive Integrated Moving Average, ARIMA) 방법을 활용한 단기간의 SMP 예측 연구6)가 수행되어 왔다. 하지만 ARIMA의 경우 단기간의 예측 정확도는 높지만 장기간의 예측은 오차가 커지는 단점7)이 있다. 이러한 문제점을 해결하기 위하여 최근 기계학습(Machine Learning)을 활용한 연구가 수행되고 있다. 인공신경망(Artificial Neural Network)을 활용한 SMP 예측 연구8,9), MLP (Multilayer perceptron) 및 NARX (Nonlinear Autoregressive Exogenous)를 활용한 SMP 예측 연구10)가 수행되었다.
기계학습의 예측 정확도 향상을 위해 데이터 필터링 방안에 대한 연구가 수행되었다. SMP의 변동성이 큰 부분을 평균화하고 필터링한 데이터와 NARX를 활용한 SMP 예측 연구11), SVR (Support Vector Regression)과 순환신경망을 기반으로 하는 LSTM (Long-Short Term Memory)을 이용한 평일, 주말, 공휴일의 단기간 SMP를 예측하는 연구12)와 변동성이 큰 휴일을 제거하여 SMP의 변동성을 예측하는 연구13)가 수행되었다. 이들 연구에서는 SMP 추세 예측 시 전력 수요, GDP, 발전원 구성 등 다양한 변수를 투입하여 SMP의 예측 정확도를 높였다. 하지만 추세 예측에 변수들의 예측 값이 필요하며 예측 값이 추세 예측 오차로 작용한다는 한계가 있었다. 또한 신재생 에너지 발전설비 중 태양광 패널과 풍력발전기의 생애주기(Life Cycle)가 보통 약 20년 또는 그 이상임에도 기존 연구는 1년 이하의 단기 예측에만 집중하고 있음을 고려한다면 발전설비의 생애주기에 대한 경제성 분석을 수행하는데 한계가 있다. 또한 경제성 분석을 수행하는데 기존의 고정 SMP나 단순회귀 분석 등을 이용한 방법은 SMP의 장기의 변동성과 추세 변화를 반영하지 못하는 한계가 있다.
본 연구의 목적은 기계학습을 이용한 신뢰성 있는 장기 SMP 추세 분석 방법을 제공하여 신규 투자자 혹은 기존 사업자가 경제성 분석 시 이러한 방법을 활용할 수 있도록 도움을 주는 것이다. 이를 위하여 2010년부터 2019년까지의 공공데이터와 세계은행(World Bank)의 2019년 보고서 데이터14)를 기반으로 기계학습을 수행하여 육지 SMP의 장기적인 추세를 분석 하고자 한다.
2. 연구 방법
Fig. 1은 연구방법과 전체적인 흐름을 나타내는 순서도이다. SMP 추정은 Fig. 1의 순서로 이루어지며 그 절차는 다음과 같다. 첫째, 육지 SMP의 장기적인 추세를 분석하기 위해 데이터를 수집하고 상관성 분석을 실시한다. 둘째, 높은 상관관계를 갖는 변수를 선정하고 이를 기반으로 기계학습을 수행한다. 셋째, 데이터의 분석 기간에 따라 분석 케이스(Case)를 두 가지로 나누어 기계학습을 수행하고 분석 기간에 따른 결과의 차이를 비교·분석한다. 넷째, 분석 케이스에 따라 기계학습된 모델로 육지 SMP의 장기 추세를 분석한다.
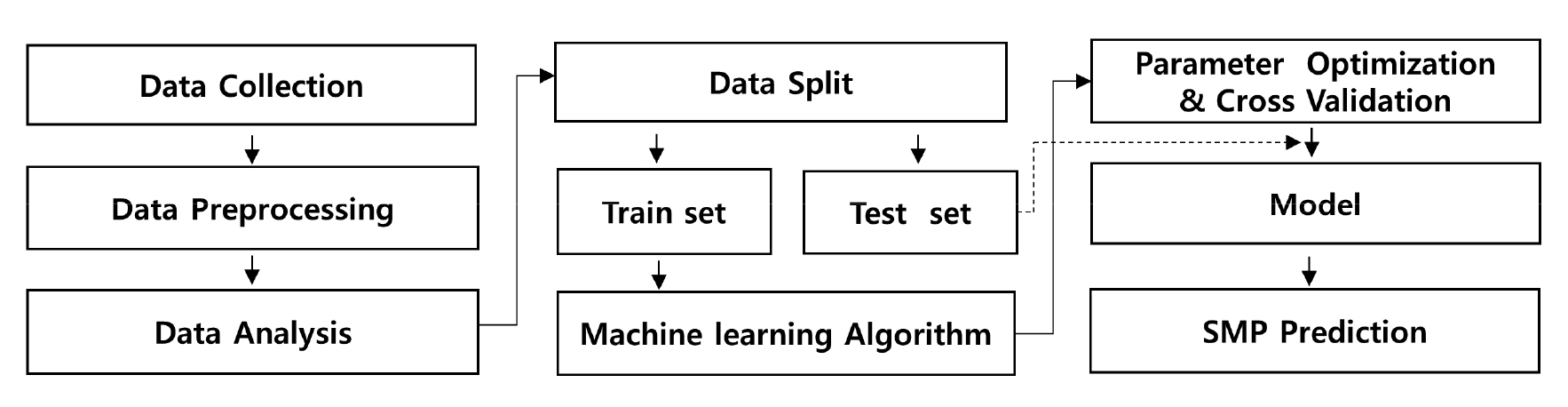
2.1 분석대상 선정
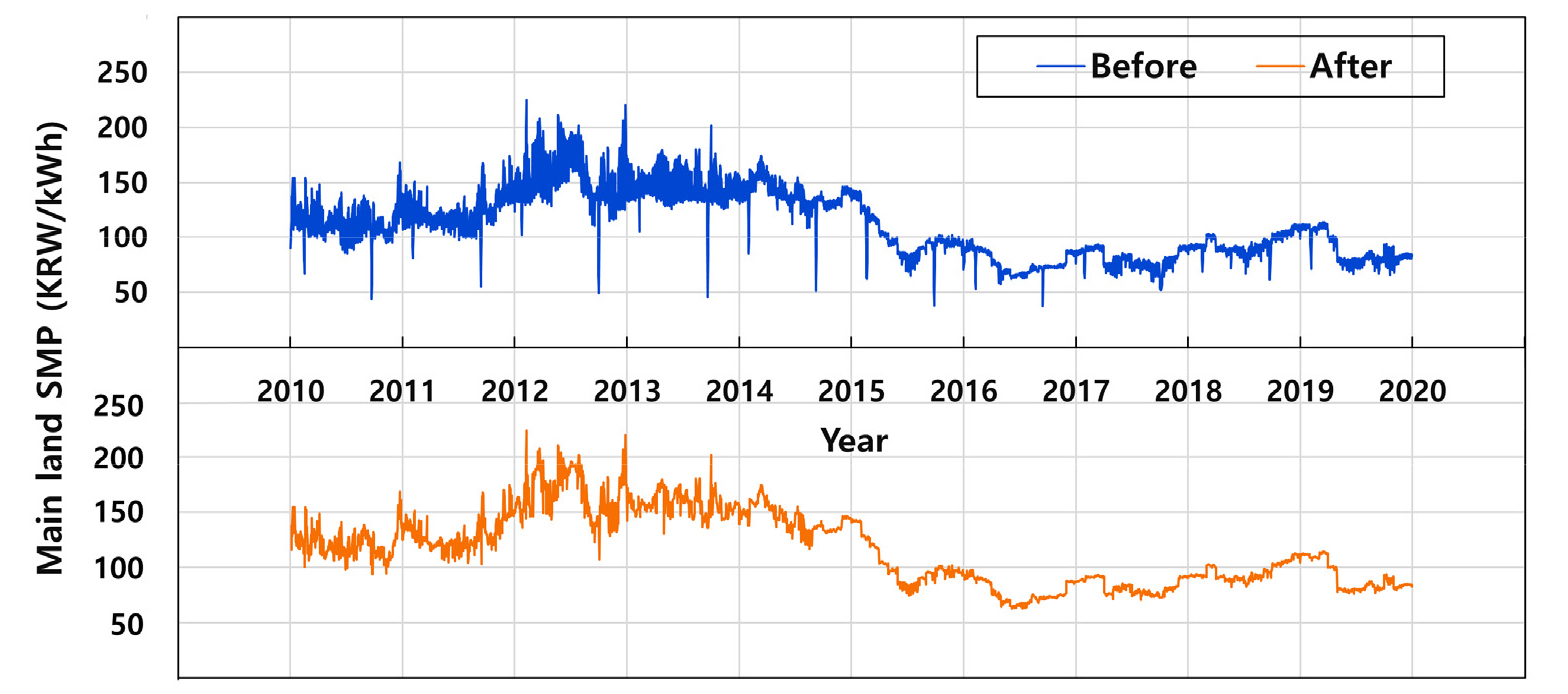
선행연구11,12,13)는 SMP 데이터의 필터링(Data Filtering)을 통하여 기계학습의 예측정확도를 향상시켰다. 이 연구에서는 필터링 방법 중 휴일을 제거하고 평일 데이터만을 활용하는 필터링 기법13)이 적합하다고 판단하여 일별 육지 SMP 데이터에서 휴일과 공휴일을 제거하였다. Fig. 2는 수집된 육지 SMP의 모든 데이터와 휴일과 공휴일을 제거한 육지 SMP 데이터의 시계열을 보여준다. 이분산성이 제거된 것을 그림을 통해 확인할 수 있으며 필터링 된 데이터를 활용하여 육지 SMP의 장기추세 분석 및 예측을 수행하였다. 또한 그림에서 2010년부터 2014년까지의 변동성이 크게 나타나는데 이는 제한된 발전공급능력, 전원구성의 첨두부하인 LNG와 유류 발전의 높은 비중과 높은 가격 변동성 등의 영향15)으로 판단되며 2015년부터 발전공급능력이 증가하여 변동성은 줄어들었다.
전력거래소에서 전날 예측한 익일의 전력수요의 공급 용량 입찰에 발전사업자가 참여하게 되며 저렴한 발전원부터 값 비싼 발전원의 공급용량을 순서대로 투입하여 수요와 공급이 일치하는 시점의 발전원에 의해 SMP가 결정된다. Table 1은 2010년부터 2019년까지의 발전원별 육지 SMP 결정 횟수를 보여준다. LNG는 10년간 평균 7,670시간으로 육지 SMP를 가장 많이 결정하였으며 1년이 8,760시간임을 감안하면 이는 매우 높은 수치이다. 5개의 발전원 중 원자력은 가장 저렴한 기저 부하 발전원이므로 SMP 결정 횟수에는 영향을 주지 못한 것으로 판단된다.
Table 1.
Number of Year SMP Deciding
| Period | LNG | Oil | Bituminous coal | Anthracite coal | Nuclear |
| 2010 ~ 2019 | 7,670 | 636 | 149 | 309 | 0 |
Table 2는 본 연구를 위해 수집된 데이터의 기간과 제공주기를 보여준다. 공공데이터 포털15)을 통하여 일 평균 육지 SMP, 전력의 수요와 공급의 변동을 알 수 있는 공급용량(Capacity), 최대전력(Max Power), 공급예비력(Supply reserve)의 일평균, 발전용 LNG가격, 서부 텍사스 중질유(West Texas Intermediate Crude Oil, WTI) 선물가격, 유연탄 가격 중 하나인 FOB Kalimatan 가격 데이터를 수집하였다. 단, 변수 선정의 일관성을 유지하기 위하여 육지 SMP와 수집된 발전원 가격의 정산시점에 대한 선‧후행 지수는 반영하지 않았다. 주기가 다른 데이터를 분석에 사용할 때, 월별 데이터의 값을 일정한 일별 데이터로 변화하여 사용하였다.
Table 2.
Period and Frequency of Collected Data Set16)
| Items | SMP | Supply reserve | Capacity | Max Power | LNG | WTI | FOB Kalimatan |
| Period | 2010 ~ 2019 (10 years) | ||||||
| Frequency | Daily | Daily | Daily | Daily | Monthly | Daily | Weekly |
2.2 투입 변수
변수 선정을 위하여 SMP에 대한 피어슨 상관계수(Pearson’s Correlation Coefficient, R)를 산출한 결과를 Table 3에 나타낸다17). 육지 SMP와 상관성이 높은 데이터는 발전용 LNG와 WTI 선물가격이었으며 상관계수는 각각 0.91, 0.80이었다. 사용된 데이터가 실제로 발전에 사용되는 발전용 LNG 가격이고, 또한 국제원유시장에서의 가격을 대표하는 유종 중 하나인 WTI 선물가격이므로 상관계수가 높게 산출된 것으로 판단된다. 따라서 육지 SMP와의 상관계수가 0.8이상인 발전용 LNG와 WTI 선물가격을 기계학습의 투입변수로 활용하였다.
3. 기계 학습 및 장기 추세 분석 결과
3.1 기계학습
연구에서 사용한 실험 환경은 Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60 GHz CPU, 64 GB RAM, Window 10 64 bit인 PC이다. 분석 프로그램은 Python 3.8.3을 사용하였다. 기계학습을 학습을 수행하기 위해서는 분석 데이터를 학습 데이터(Train Data)와 시험 데이터(Test Data)로 분류하여야 한다. 따라서 2절에서 전처리한 2010년부터 2019년까지의 데이터 중 일부를 학습데이터로, 나머지는 시험데이터로 나누어 기계학습을 수행하였다. 학습 정확도의 검증을 위해 학습 데이터의 10%를 랜덤으로 추출하여 검증 데이터(Validation Data)로 활용하였고 교차검증(Cross Validation)을 통하여 모델을 학습하였다. 또한 시험 데이터는 학습된 모델의 예측 정확도를 확인하기 위해 사용되었다. 학습 및 예측 정확도를 수치적으로 평가하기 위한 지표로 평균제곱근오차(RMSE)와 결정계수(R2)를 활용하였다18). R2은 값이 1에 가까울수록 모델의 정확도가 높음을 보여주고, RMSE는 실제 값과 예측 값의 차이를 나타내므로 작을수록 정확도가 높음을 나타낸다. 장기 예측에 따른 오차를 줄이기 위해 평가지표의 결과를 통해 예측 정확도가 높은 모델을 선정하고 이를 활용하여 육지 SMP의 장기 추세를 분석하였다.
3.2 데이터 셋 및 기계학습 모델 선정
Fig. 3은 기계학습을 위하여 선정된 최근접 이웃 모델(K-Nearest Neighbor, KNN), Light Gradient Boost Machine (LGBM), Random Forest (RF), SVR 등 총 4가지 모델을 나타낸다19,20). KNN은 데이터로부터 거리가 가장 가까운 K개의 다른 데이터를 참조하여 분류하는 알고리즘이며, 하이퍼 파라미터(Hyper Parameter)의 수가 많지 않아 구현하기가 쉽다. LGBM은 최대 손실 값을 갖는 부분에서 리프 중심 트리 분할(Leaf Wise)을 함으로써 정확도가 높고 기계학습을 수행하는 시간이 적다는 장점이 있다. RF는 다수의 결정트리(Decision Tree)를 생성하고 데이터를 무작위로 학습하여 각 결정트리마다 예측 값을 도출한다. 각 결정트리 마다 산출 값을 취합하여 최종 예측을 한다. SVR은 경계의 폭(Margin)을 통해 다양한 패턴을 분류하는 알고리즘인 SVM (Support Vector Machine)에서 회귀문제로 확장된 모델이며 선형회귀(Linear Regression)와 달리 비선형 문제에도 적용할 수 있다.

Fig. 4는 기계학습에 따른 입·출력 데이터 및 알고리즘을 나타낸다. 육지 SMP와 상관관계가 높았던 발전용 LNG와 WTI 선물가격을 입력 변수로 하여 4가지 알고리즘을 통해 육지 SMP를 예측하도록 학습하였다.

학습 데이터의 기간에 따른 변화를 분석하기 위해 10년간의 데이터를 사용한 케이스 A와 2015년부터 2019년까지 5년간의 데이터를 활용한 케이스 B로 구분하여 기계학습을 수행하였다. Table 4는 케이스 A와 B에 대한 기간을 나타낸다. 케이스 A의 학습 데이터는 2010년부터 2018년까지의 데이터가 사용되었고 시험 데이터는 2019년의 데이터가 활용되었다. 케이스 B의 학습 데이터는 2015년부터 2018년까지 총 4년의 데이터가 활용되었고 시험 데이터는 2019년의 데이터가 사용이 되었다.
Table 4.
Train and Test Periods
3.3 기계학습의 결과
RMSE와 R2을 활용하여 기계학습의 학습 정확도를 확인하였다. Table 5는 케이스 A와 B의 학습과정에서의 교차검증 결과를 보여준다. 케이스 B가 케이스 A보다 학습정확도가 높은 것을 알 수 있다. 이는 2015년 전·후 SMP 변동성 크기의 차이가 학습의 방해 요소로 작용한 것으로 판단된다.
Table 5.
Train Result of Cases A and B
| Cases | Items | KNN | LGBM | RF | SVR |
| A | RMSE | 8.410 | 11.406 | 13.070 | 13.471 |
| R2 | 0.937 | 0.884 | 0.848 | 0.838 | |
| B | RMSE | 4.187 | 5.342 | 5.545 | 7.136 |
| R2 | 0.977 | 0.962 | 0.959 | 0.932 |
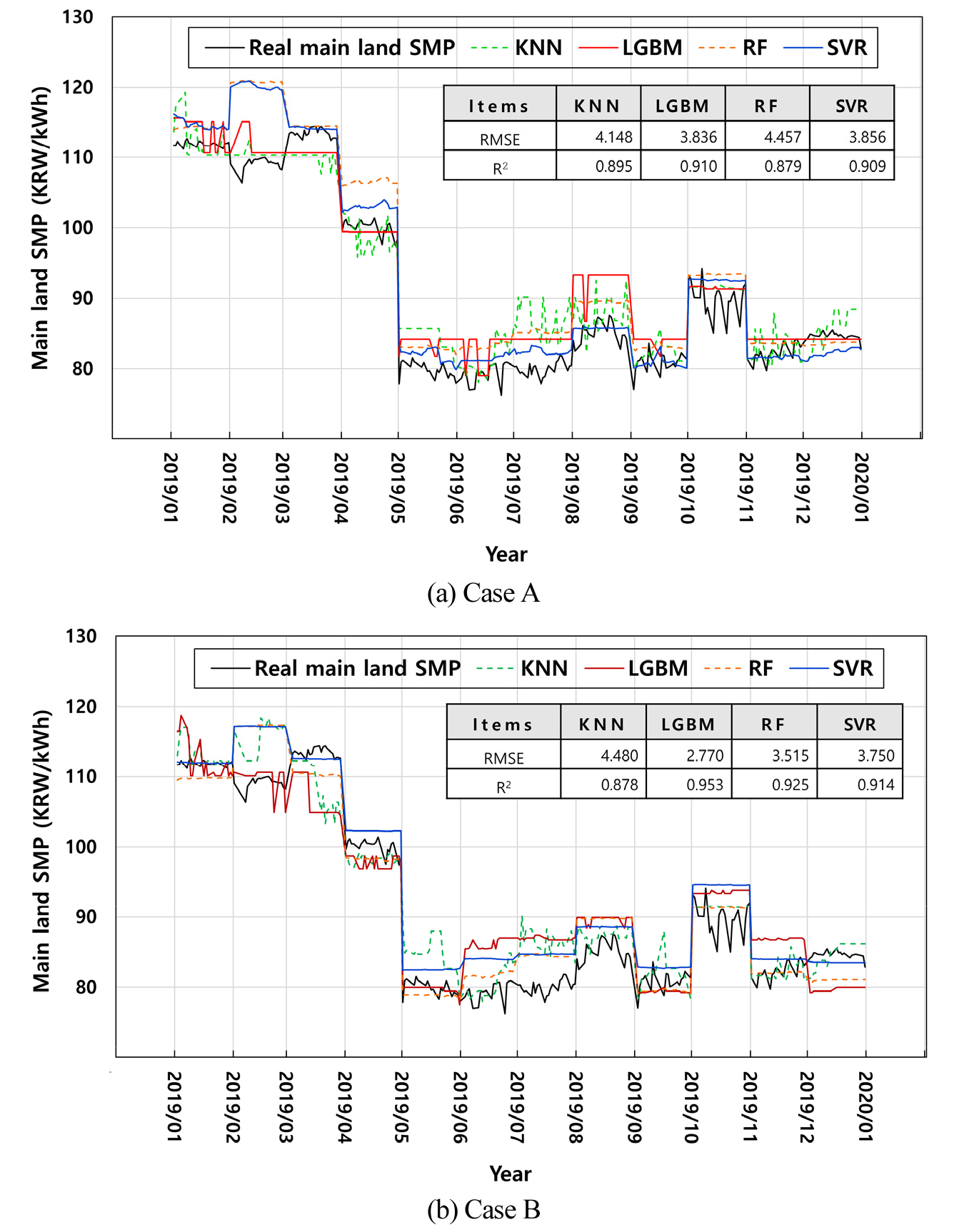
Fig. 5는 케이스 A와 B의 2019년 육지 SMP 예측 결과를 보여준다. 4개의 모델 모두 육지 SMP의 추세를 적절히 추정하는 것으로 보인다. 예측 정확도 평가를 위하여 RMSE와 R2을 평가지표로 사용하였다. 그 결과 케이스 A와 B에서 LGBM의 RMSE가 각각 3.836 KRW/kWh과 2.770 KRW/kWh이었고 R2은 0.910과 0.953으로 예측정확도가 가장 높았다. 이 그림과 같은 패턴은 기계학습 모델의 특성과 Table 2에 나타낸 데이터의 주기로 인한 결과이다. 즉, LGBM과 SVR은 상관성이 높은 월별 데이터인 발전용 LNG가격의 가중치가 높아 월별 데이터의 특성이 크게 반영되었으며, RF와 KNN은 입력 데이터의 상관성에 따라 가중치를 두는 것이 아니므로 월별 데이터인 발전용 LNG가격의 특성뿐만 아니라 WTI 선물가격의 특성이 추가적으로 반영된 것으로 판단된다. 이 연구를 위하여 케이스 A, B에서 예측 정확도가 가장 높았던 LGBM을 활용하였다.
3.4 SMP의 장기 추세 예측 결과
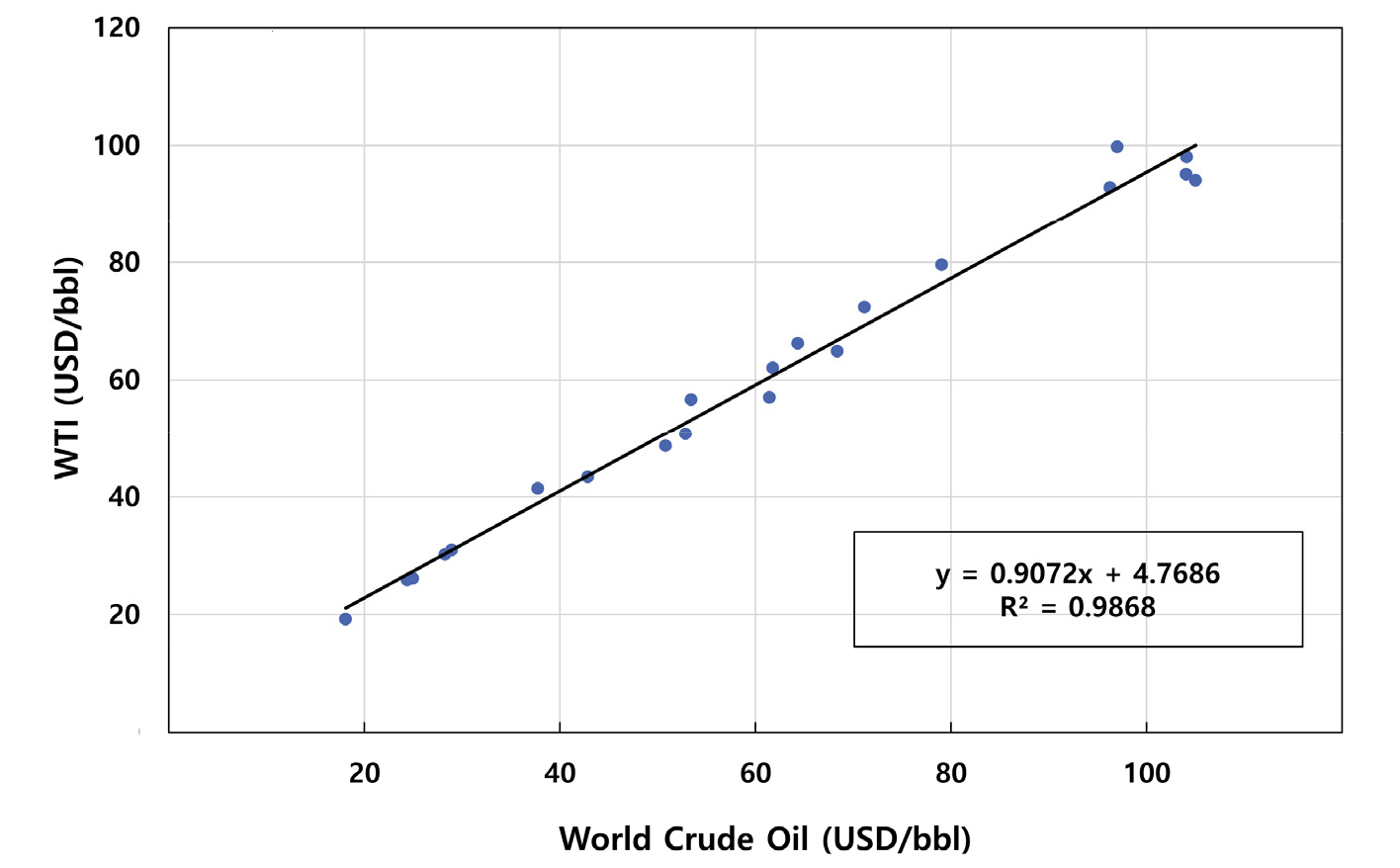
장기추세 분석 및 예측의 입력변수로 발전용 LNG와 WTI 선물가격을 활용하기 위해서는 두 변수의 장기 전망치가 필요하다. 이를 위하여 2019년 세계은행에서 보고한 2020년부터 2030년까지의 두바이(Dubai)유, 브렌트(Brent)유, WTI의 평균가격인 국제원유(World Crude Oil) 가격 전망치와 일본 LNG 가격 전망치를 활용하였다. 1999년부터 2018년까지 국제원유 가격 평균치와 WTI 선물 가격에 대해 선형회귀 분석을 수행한 결과를 Fig. 6에 보여준다. 이 둘의 결정계수는 0.9868로 매우 높은 것으로 분석되었고 이를 통해 도출된 회귀식을 사용하여 WTI선물가격을 추정하였다.
국내에 수입되는 LNG의 중장기 물량에 대한가격은 일본의 원유수입가격(Japan Crude Cocktail)을 기준으로 하는 경우가 많으며 일본 LNG 가격이 먼저 발표된 이후에 대금을 정산하므로 한국의 발전용 LNG 가격과 일본 LNG 가격에 대해 분석하였다. 일본 LNG 가격의 단위는 USD/mmbtu인데 반해 한국 발전용 LNG 가격의 단위는 KRW/GJ이다. 따라서 이를 보정하기 위하여 단위환산과 연간환율을 적용하였다.
Fig. 7은 2010년부터 2019년까지의 한국 및 일본의 LNG 가격과 시점을 보정한 일본의 LNG가격에 대한 추세를 보여준다. 동북아시아의 LNG 수입 가격은 일본 원유수입가격(Japan Crudeoil Cocktail)을 약 4개월 이상 후행하는 것으로 알려져 있다. 가격 후행 이외에도 환율의 적용시점, 예상치 못한 수요 변화, 자연재해 등의 다양한 외부 요인을 고려했을 때 한국의 발전용 LNG 가격은 일본 LNG 가격을 약 1년정도 후행하는 것으로 분석되었다. 따라서 상관성 분석을 위하여 일본 LNG 가격의 시점에 대한 보정을 수행하였다. 시점 보정 전 후의 일본 LNG 가격과 한국 발전용 LNG 가격의 상관계수는 각각 0.53, 0.96으로 보정 후 상관관계가 매우 개선되었다. 2020년 발전용 LNG 가격 추정에 따른 연간환율은 2020년 연간환율인 1,179.90원을 사용하였고 2021년부터 2030년까지의 연간환율은 2021년 2월 2일 매매 기준 환율인 1,101.64원을 사용하였다. 일본 LNG 가격 전망치에 이를 반영하고 단위를 환산하여 발전용 LNG 가격의 전망치를 추정하였다. 추정된 한국 발전용 LNG가격과 WTI 선물가격의 전망치를 활용하여 SMP 장기 추세 분석 및 예측을 수행하였고 환율의 변동, 유가 변동 등으로 인한 전망치 오차는 발생할 수 있을 것으로 생각된다.
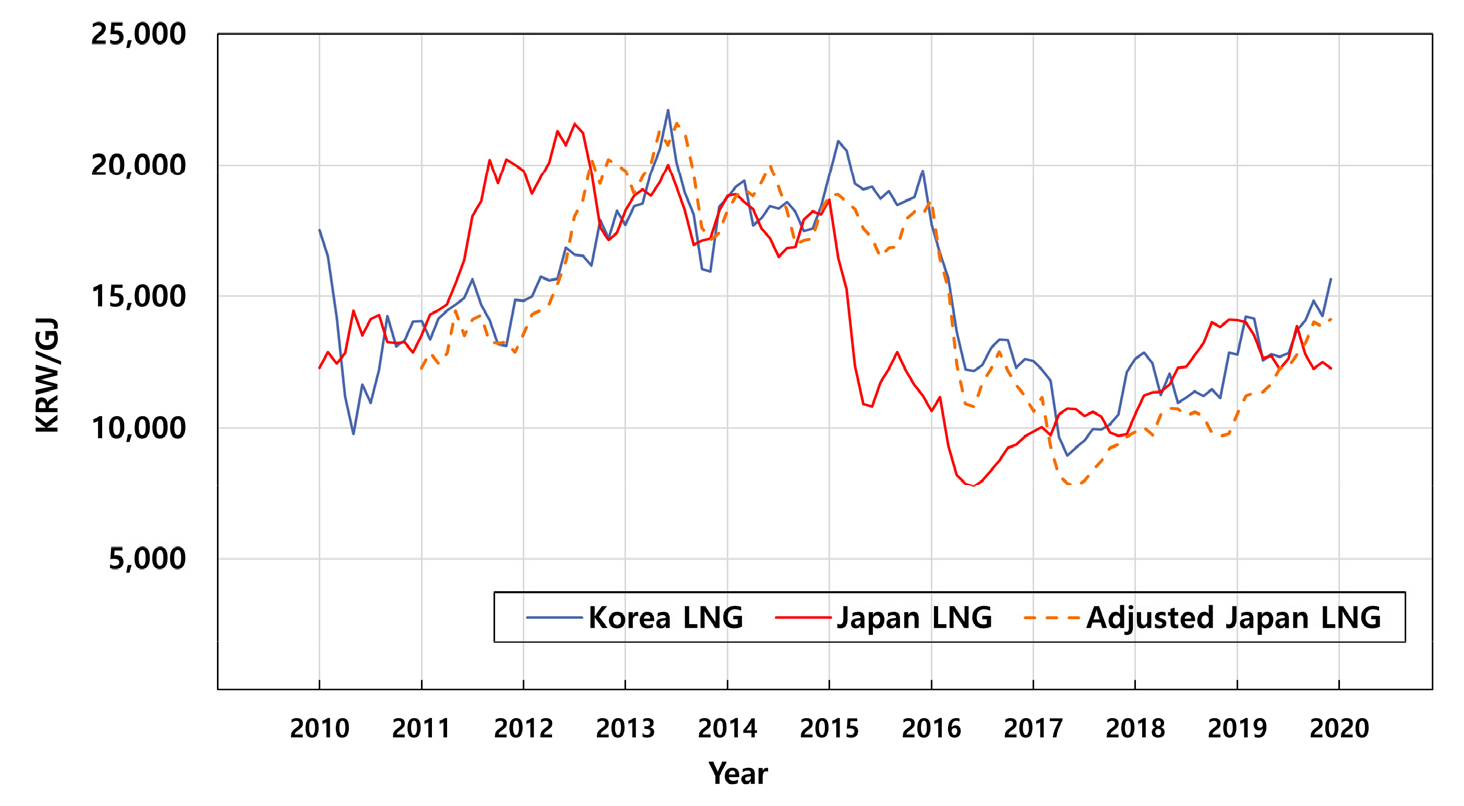
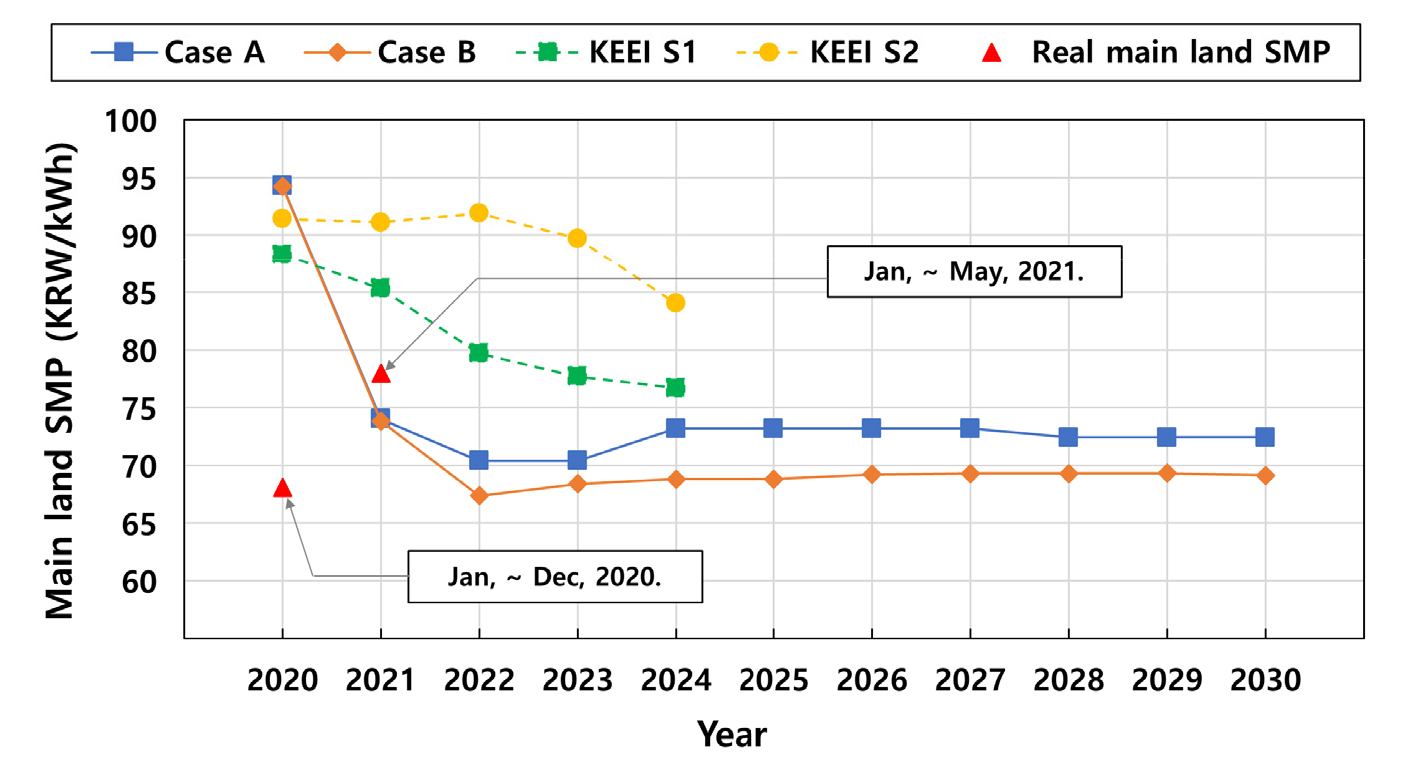
Fig. 8은 추정된 한국의 발전용 LNG 가격 및 WTI 선물가격과 기계학습을 활용하여 육지 SMP의 장기추세 분석을 수행한 결과를 보여준다. 2020년부터 2030년까지 케이스 A와 B 모두 장기적으로 SMP가 감소하여 각각 평균 72 KRW/kWh, 69 KRW/kWh 선에서 유지되는 것으로 예측되었다. 한국에너지경제연구원(KEEI)의 2015년 보고서21)에 따르면 S1과 S2의 시나리오를 통해 2016년부터 2024년까지 SMP가 장기적으로 감소할 것으로 전망되었고 이는 본 연구의 SMP 추세 예측 결과와 비슷하였다. 실제 2020년 육지 SMP와 케이스 A와 B의 2020년 육지 SMP 전망치의 예측오차는 모두 약 26 KRW/kWh로 크게 발생하였고, 이는 COVID-19로 인한 특수 상황과 유가의 큰 변동으로 육지 SMP의 변동이 매우 컸기 때문이라고 생각된다. COVID-19로 인한 상황과 유가 변동이 2020년보다 조금 안정된 2021년 1월부터 5월까지의 실제 육지 SMP 평균치는 약 78 KRW/kWh으로 케이스 A와 B의 전망치인 약 74 KRW/kWh와 4 KRW/kWh정도 차이가 있었다.
4. 결 론
본 연구는 데이터 분석 기간에 따라 두 가지 케이스로 나누어 기계학습 방법을 활용한 육지 SMP의 장기적인 추세를 분석하였으며 그 결과는 아래와 같다.
(1) 기계학습을 위한 변수선정을 위하여 다양한 변수와 육지 SMP에 대한 상관분석을 수행한 결과, 다양한 데이터 중 발전용 LNG 가격과 WTI 선물가격이 육지 SMP와 높은 상관성을 보임을 확인하였고 두 인자를 기계학습에 활용하여 육지 SMP의 장기추세를 분석하였다.
(2) 케이스 A와 B의 학습기간은 각각 10년, 5년이었다. RMSE와 R2으로 예측정확도를 확인한 결과, 두 케이스 모두 다양한 모델 중 LGBM 모델이 예측정확도가 가장 높았으므로 육지 SMP의 장기추세 분석에 이를 사용하였다. 케이스 A보다 케이스 B의 예측정확도가 더 높았다. 이는 일정 기간 이상의 데이터에 상이한 변동성의 특성이 공존하는 경우, 장기간의 데이터가 오히려 학습의 방해요소로 작용하는 것을 보여주며 2015년 전후의 육지 SMP의 변동성의 크기 차이로 인해 케이스 A는 낮은 예측 정확도가 나타난 것으로 판단된다.
(3) 일본 LNG 가격과 국제원유 평균치를 활용하여 한국의 발전용 LNG와 WTI 선물가격을 예측하였고 이를 활용하여 육지 SMP의 장기 추세를 분석하였다. 그 결과, 케이스 A와 B의 육지 SMP는 2020년부터 2022년까지 감소하는 추세를 보이다가 2023년부터 2030까지 각각 평균 72 KRW/kWh, 69 KRW/kWh에서 유지되는 것으로 분석되었다.
추후 기계학습을 이용한 장기 REC 예측 연구를 수행하여 본 연구의 결과와 융합 연구를 진행한다면 장기 가격계약제도의 계약금액 예측과 장기 가격계약 종료 후 REC 미지급 상황에서 사업자의 수익 예측 등 다양한 경제성 분석 연구를 수행할 수 있을 것으로 기대된다.
