

1. 서 론
2. 클러스터링 방법
2.1 위치와 일사량을 고려한 클러스터링
2.2 발전량 히스토리를 활용한 클러스터링
3. 클러스터링 결과
3.1 위치와 일사량을 고려한 클러스터링 결과
3.2 발전량 히스토리를 활용한 클러스터링 결과
4. 결 론
기호 및 약어 설명
K : 군집의 수
means : 평균
Clustering : 유사한 특성을 가진 객체들을 군집화하는 작업
Inertia : 각 샘플과 가장 가까운 클러스터 중심 사이의 거리 제곱 합
scaled : 정규화 값
: 원본 값
: 최대값
: 최소값
: 데이터 포인트의 총 개수
: 데이터 세트의 i번째 포인트
: 클러스터 세트
: 클러스터 j의 중심
1. 서 론
정부는 2017년부터 신재생에너지 통합 모니터링시스템(REMS: Renewable Energy Monitoring System) (이하 ‘REMS’) 개발을 시작하여 2018년부터 정부 지원 사업으로 보급되는 자가용 설비에 대한 모니터링을 Table 1과 같이 실시하고 있다1). REMS는 당초 설비 소유주와 지자체에게 설비의 고장 유무를 안내하기 위한 서비스로 시작되었으나, 신재생에너지 보급 규모가 증가하면서 국가 전력망에 미치는 영향이 커짐에 따라 상업용 태양광 설비 뿐만 아니라 자가용 태양광 설비의 발전량 예측도 중요해지고 있다2). 2024년 4월 현재, REMS에는 13만 개 이상의 태양광 설비가 연결되어 있다. 이러한 다수의 소규모 설비의 발전량을 개별적으로 예측하는 것은 경제적 효율성이 떨어지며, 자가용 설비에는 높은 수준의 정확성이 요구되지 않는다. 따라서, 적정수준의 모니터링 기법이 필요한 실정이다. REMS에 연결된 설비는 대부분 정부 지원 사업을 통해 보급된 소규모 자가용 설비로, 주거 또는 상업 시설에 설치되어 있다. 이 중 Table 2와 같이 주택 태양광 설비가 약 78%를 차지하며, 나머지 22%는 중대형 건물에 설치되어 있다3). 국내의 지형적 특성과 주택 태양광 설치 조건(약 20 m2 면적 필요)을 고려할 때, 주택 태양광 설비는 옥상 또는 마당이 있는 단독주택 단지나 타운하우스 구역 등에 밀집되어 설치되는 경향이 있다. 따라서 13만 개 이상의 설비의 발전량을 효과적으로 예측하기 위해서는 클러스터링 기법이 필수적이다.
Table 1
Monitoring status of Regional PV Systems in REMS
Table 2
Installation types of PV Systems in REMS
최근에는 태양광 발전량 예측을 위한 다양한 방법론이 제시되고 있으나, 정부 보급사업으로 수년간 보급된 자가용 태양광의 발전량을 효율적으로 예측하기 위한 연구는 부족하여 REMS에 연결된 태양광 설비데이터를 활용하여 본 연구를 진행하였다. 또한 지역 단위의 태양광 발전량 예측을 위한 다양한 기법이 개발되고 있으며, 지역 단위의 측정 데이터를 확대적용(Upscaling)하여 예측의 불확실성 및 오차를 줄이기 위한 시도가 이루어지고 있다4).
본 연구에서는 REMS 연결된 소규모 태양광 약 13만개 설비의 효율적인 발전량 예측을 위해 국내 지자체 중 지리적으로 중심에 위치하고, REMS에 연결된 지자체별 태양광 설비 순위 중에 중위권에 위치하고 있는 충청북도를 우선 대상지로 선정하였다. 충청북도 지역의 11,268개 발전소를 그룹화하고 각 그룹의 대표 발전소를 선정하는 것을 목표로 하였다. 클러스터링 알고리즘은 발전소 그룹화를 위해 위도, 경도, 일사량, 고도, 발전량 이력 등 다양한 인자를 적용하며, K-means와 Autoencoder 기법을 활용하였다5,6,7,8). 첫째로, REMS에 연결된 충청북도 지역의 태양광설비 주소 정보를 활용하여 각 태양광 설비의 위치를 위도 및 경도 값으로 변환하고 해당 위경도 값을 기반으로 각 위치의 고도 및 일사량 정보를 추출하여 클러스터링 분석에 활용하였고, 둘째로, 2023년 1월 ~ 12월 발전 이용률 데이터를 활용하여 정상 가동설비를 찾고, 이를 대상으로 발전량 패턴 기반의 클러스터링을 수행하는 방법론을 제시하였다.
2. 클러스터링 방법
2.1 위치와 일사량을 고려한 클러스터링
2024년 4월 기준, REMS에는 태양광 설비 약 13만 개의 데이터가 존재하며 REMS에 연동된 태양광 설비는 다음과 같은 특징을 가진다.
●무작위 위치: 주택 소유주의 자발적 설치로 인해 설비 위치가 무작위로 분포함
●증가하는 설비 수: 설치된 태양광 설비 수는 고정되지 않고 매년 3만 개 이상 증가함
●불명확한 클러스터 수: 최적의 대표 중심점 개수를 특정하기 어려움
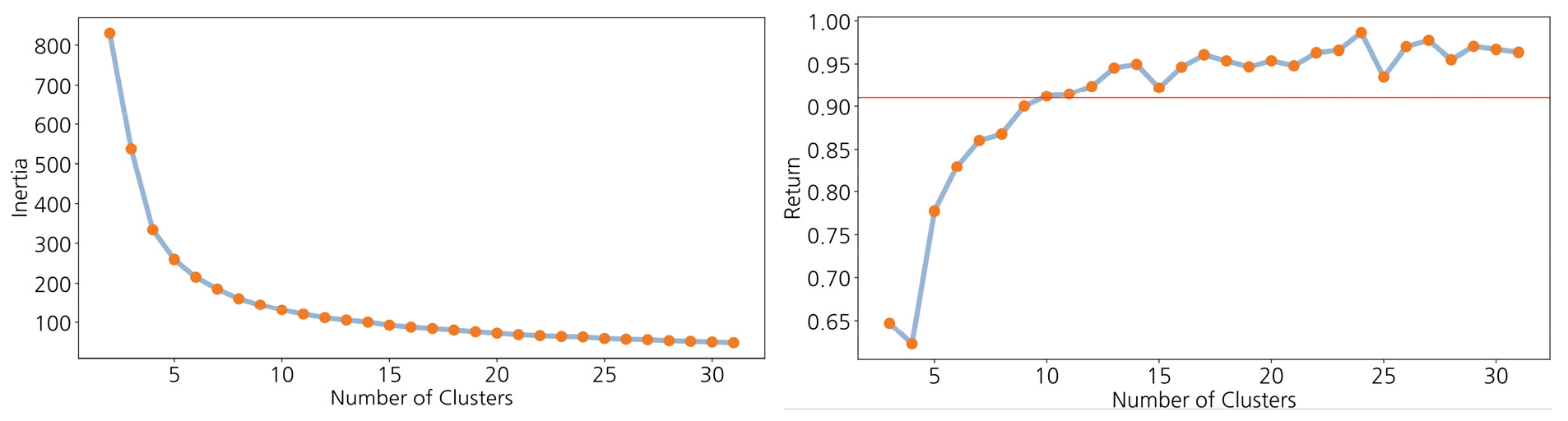
위와 같은 이유로 대규모 데이터에 주로 활용되는 K-means 클러스터링을 본 연구의 클러스터링 기법으로 활용했다. 광역단위에서 REMS에 연결된 태양광 발전 설비 데이터를 군집화하고, 각 군집의 발전량 패턴을 살펴보았다. K-means 클러스터링에서 최적의 군집 개수 K를 결정하는 것은 중요한 문제로 일반적으로 K값이 증가할수록 Inertia는 감소하지만, 특정 K값 이후에는 감소폭이 크게 줄어들게 된다. 이러한 변화가 팔꿈치 모양과 유사하다고 하여 Elbow Method라고 불리며, Inertia는 식(1)로 정의된다.
본 연구에서는 클러스터링 수에 따른 Inertia 변화를 기반으로 적절한 클러스터 수를 결정하는 Elbow Method의 객관성을 높이기 위해 다음과 같은 return ratio 지표를 식(2)로 제시한다.
위에서 설명한 방법론을 적용하여 충청북도의 태양광 발전 설비에 대한 클러스터링을 수행하였다. 클러스터링 결과를 시각화하고, 각 군집의 특성을 분석하여 태양광 발전량 예측 모델 구축에 활용할 수 있는 정보를 도출하였다.
2.2 발전량 히스토리를 활용한 클러스터링
발전량은 REMS에 표시된 2023년의 각 발전량 설비의 발전 이력을 인자(factor)로 하였다. REMS는 미가동되는 설비, 통신 이상으로 발전량 데이터가 없는 설비, 중고인버터로 인해 발전량 데이터가 정상치를 벗어나는 설비가 존재한다. 본 연구는 정상가동설비의 발전량 예측에 목표를 두고 있으므로 앞서 언급된 이유 등으로 인해 이용률이 정상 범위를 벗어나는 설비는 클러스터링 대상에서 제외하기로 하였다. 자가용 태양광 설비의 정상 이용률 범위는 10.01% ~ 22.21%를 활용하였다9). 발전 이력을 활용한 태양광 설비의 클러스터링은 먼저 Autoencoder를 사용하여 발전량 패턴에 있는 노이즈를 제거하고, 이렇게 얻어진 발전량 패턴의 유사성을 기반으로 클러스터링을 찾기 위해 K-means 알고리즘을 적용하였다. Autoencoder는 각 발전소의 시간대별 발전량 패턴(24차원)을 더 낮은 차원(8차원)의 특성으로 압축했다가 이를 다시 원래 차원으로 되돌림으로써 중요하지 않은 노이즈 패턴을 제거해 준다.
3. 클러스터링 결과
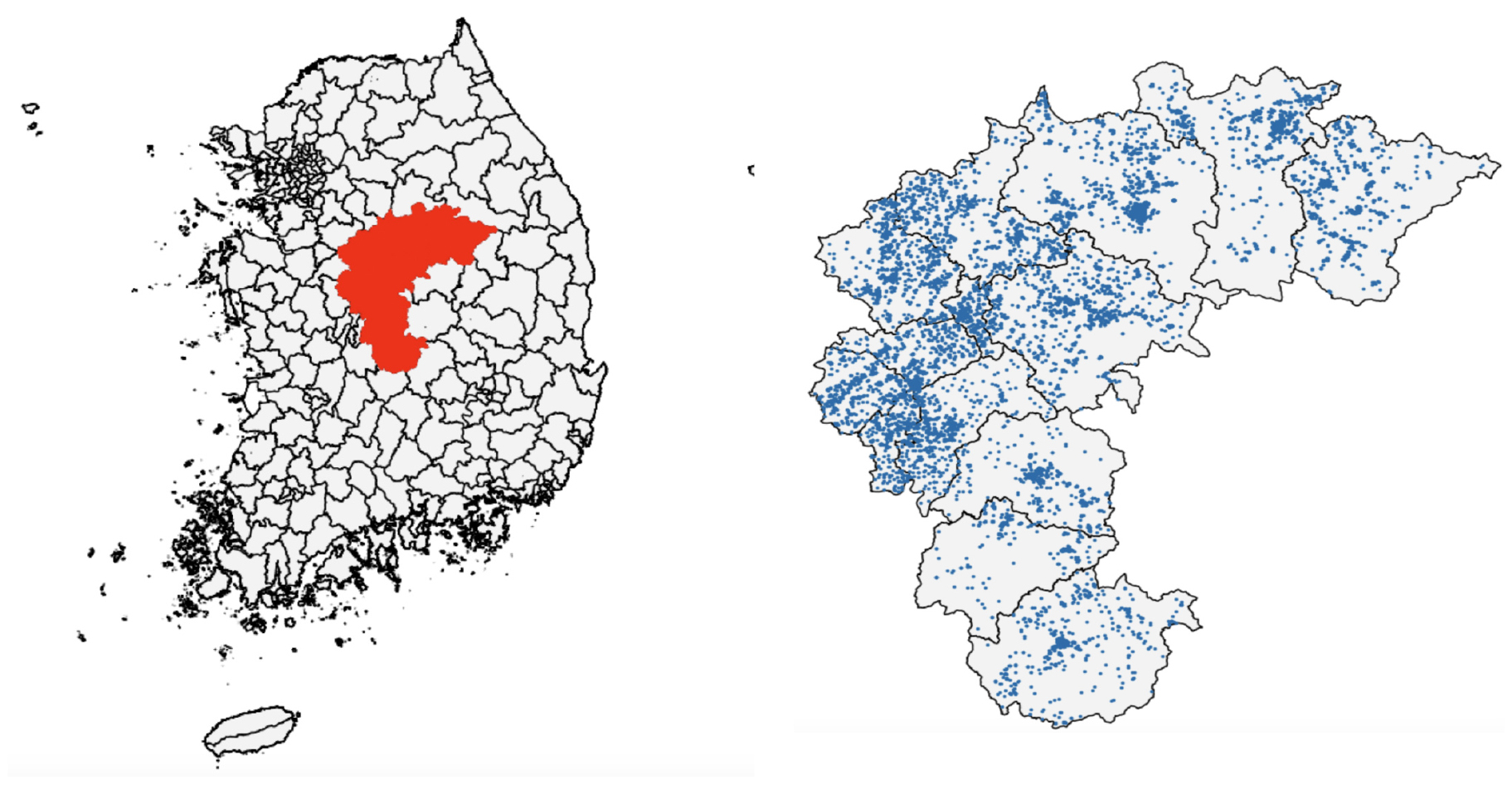
국토의 중심에 위치하며 1만 개 이상의 태양광 설비를 보유한 충청북도 지역을 대표 광역지자체로 선정하여 클러스터링을 시도하였다. 충청북도 내 태양광 설비의 분포는 그림 Fig. 1과 같다.
3.1 위치와 일사량을 고려한 클러스터링 결과
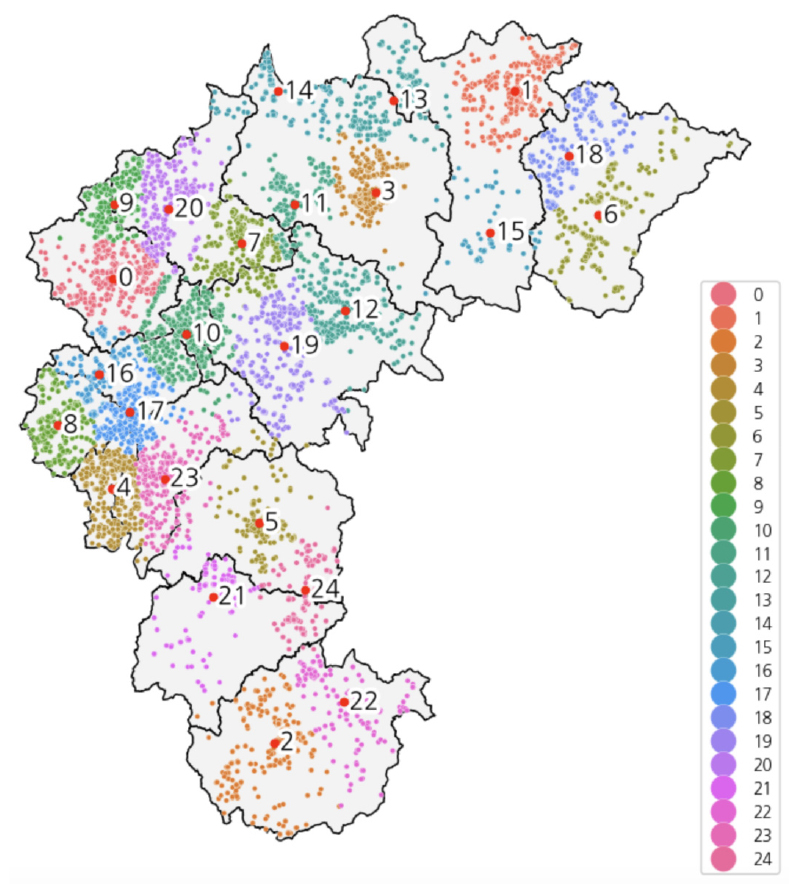
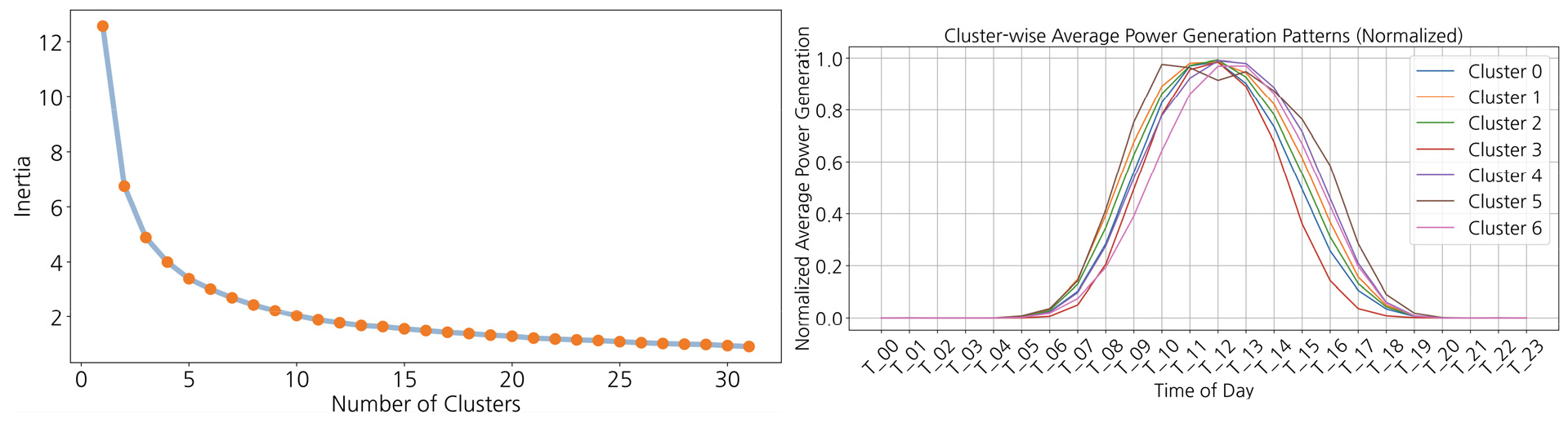
첫 번째로, 충청북도 지역 태양광 설비의 위치 정보(위도, 경도)만으로 K-means 클러스터링을 수행하였다. 군집의 수 K를 2에서 31까지 변화시키며 클러스터링을 수행하였으며, K = 25인 경우의 결과를 Fig. 2에 나타냈다. 각 군집의 중심점을 빨간 점으로 표시하였다. 군집의 수 K가 너무 적은 경우, 군집 하나에 마땅히 구분되어야 할 서로 다른 패턴들이 혼재하게 되고, 반대로 군집의 수 K가 너무 큰 경우에는 일부 군집 중심점들이 지나치게 인접하게 되어 지자체 한 곳에 과도하게 많은 군집들이 형성되는 문제가 발생한다. 이를 해결하기 위해 적절한 K를 찾는 방법으로 식(2)에서 정의한 return ratio를 활용하였다. return ratio는 군집 수 증가에 따른 Inertia 그래프에서 연속한 두 Inertia 값의 비율을 의미한다. 이 비율이 처음으로 0.91보다 커지는 K를 클러스터링에 사용할 군집의 수로 선택하였다(이 기준치는 절대적인 기준이 아니라 연구에 따라 다른 값을 적용할 수 있다. 다만 같은 연구에서는 일관적인 기준을 적용해야 한다). 설비의 위치 정보(위도, 경도)로 클러스터링할 때, 이 기준으로 최종 군집갯수 K = 11을 선택하여 최종적으로 Fig. 3과 같은 클러스터링 결과를 얻었다. Fig. 4에 군집의 수 K에 따른 Inertia의 변화 곡선(왼쪽)과 K에 따른 return ratio의 변화 곡선(오른쪽)을 표시하였다.
두 번째로, 태양광 발전량은 고도의 영향을 받을 것이므로, 위치 정보(위도, 경도) 뿐 아니라 고도 정보까지 추가하여 클러스터링을 수행하였다. 고도 데이터는 국토지리정보원 연속수치지형도 등고선 데이터를 활용하였으며, 이는 격자데이터 형태로 제공된다10). 발전소 위도와 경도를 기준으로, 100 m 단위 2차원 격자에서 구해진 등고선 데이터에서 충청북도의 고도 분포는 Fig. 5와 같으며, 25 m에서 840 m 사이에 분포되어 있다. return ratio가 0.91보다 큰 기준을 바탕으로 최종 군집갯수 K = 22을 선택하였다. 위도, 경도, 그리고 고도 데이터의 분포 범위를 Table 3에 표시하였다. 고도 값(m 단위)의 스케일이 위도, 경도 값(°단위)의 스케일에 비해 수백 배 크며, 이와 같은 이유로 Fig. 6과 같이 위․경도 보다는 고도에 의해 클러스터링이 좌우되는 결과가 나타났다.
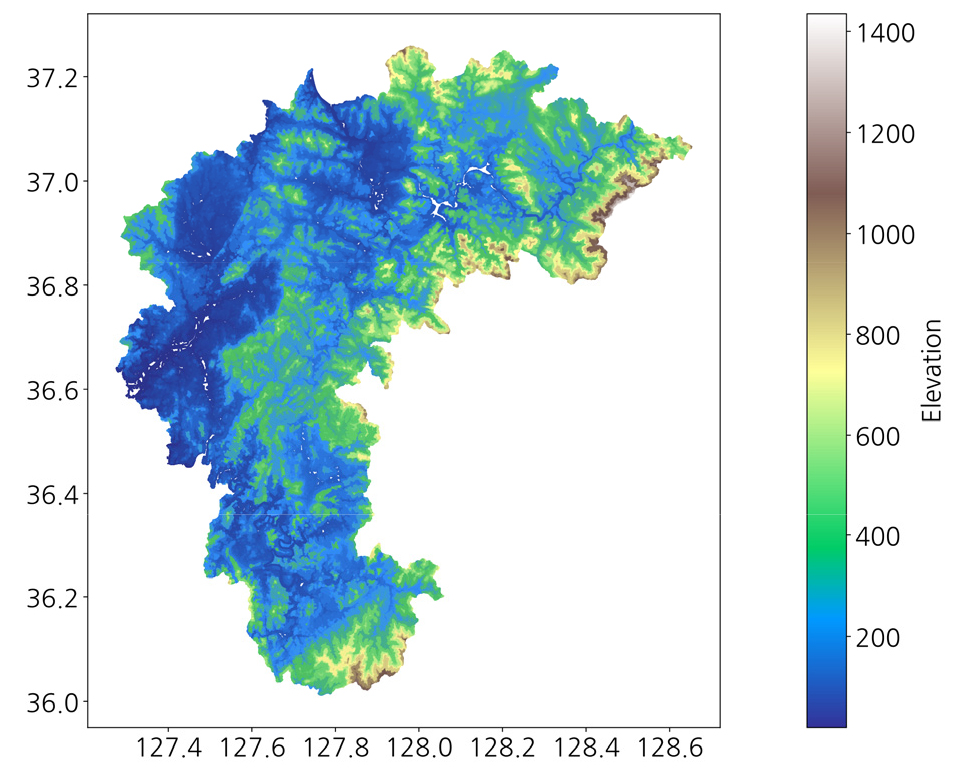
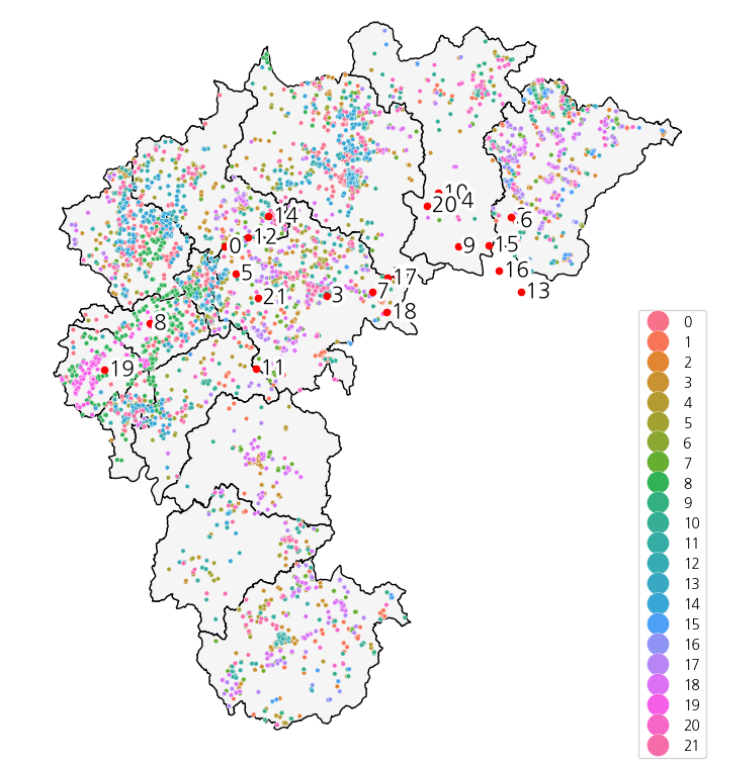
Table 3
Comparison of Scales for Latitude, Longitude, and Altitude Data
| Latitude | Longitude | Altitude | |
| Maximum Value | 36.020703 | 127.286450 | 25 |
| Minimum Value | 37.242900 | 128.614393 | 840 |
이를 해결하기 위해 각 인자별 스케일을 동일하게 조정하는 정규화 작업을 수행하였다. 정규화 작업에서는 식(3)과 같이 계산하여 변수 값의 범위를 [0, 1] 사이로 조정하였다.
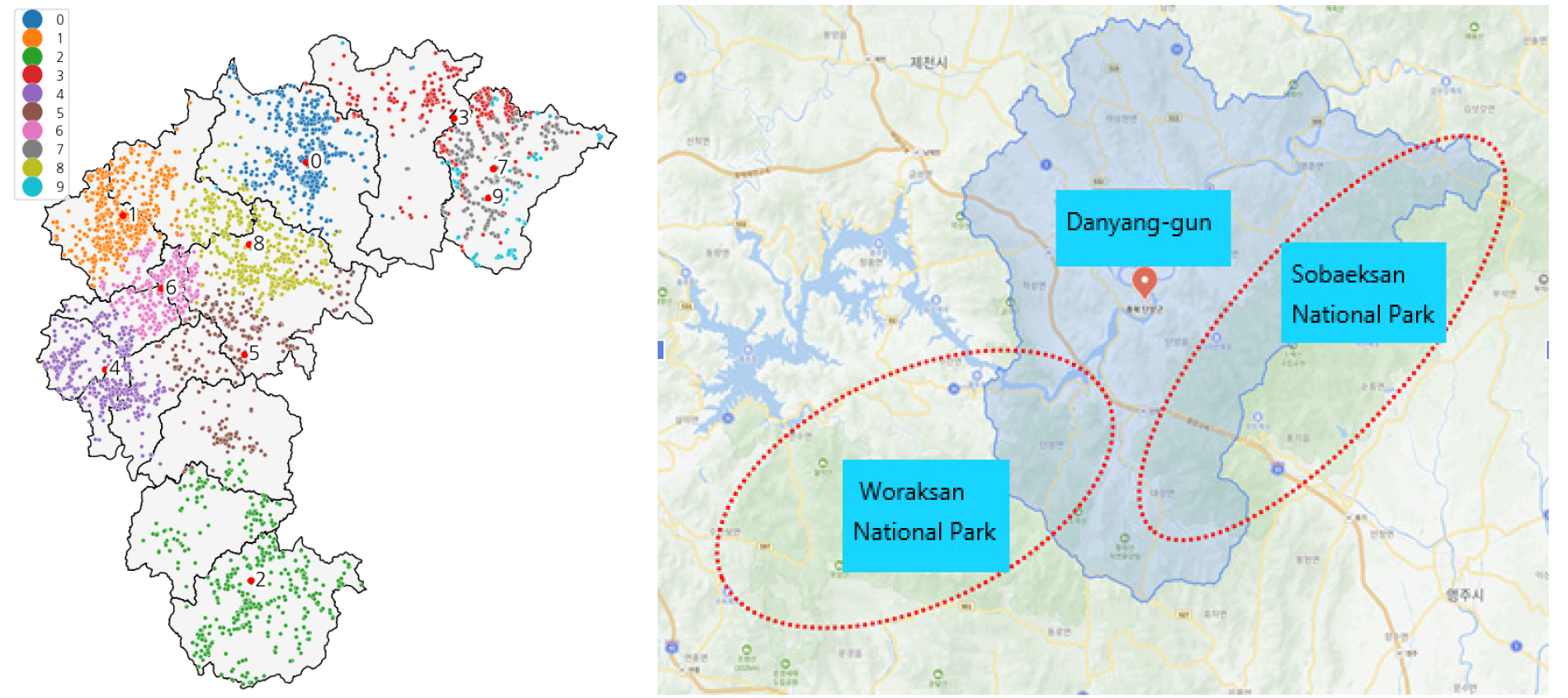
정규화 후 return ratio가 0.91보다 큰 기준을 바탕으로 클러스터링 결과(K = 9)를 설정하여 보면 Fig. 7의 왼쪽 그림과 같이 각 클러스터의 지리적 경계가 비교적 명확하게 구분됨을 확인할 수 있다. 다만, 충청북도 북동쪽 지역인 단양군에는 두 클러스터(7번, 9번)의 영역이 서로 겹치며 혼재되어 있는데, 이는 단양군이 고고도 지역과 저고도 지역이 혼재되어 있기 때문으로 보인다. 9번 클러스터는 상대적으로 고도가 높은 소백산 국립공원과 월악산 국립공원 지역(도락산)의 설비들이 대부분이며, 7번 클러스터는 대부분 그 외의 상대적으로 고도가 낮은 지역의 설비들의 집합이다(Fig. 7의 오른쪽 그림 참고).
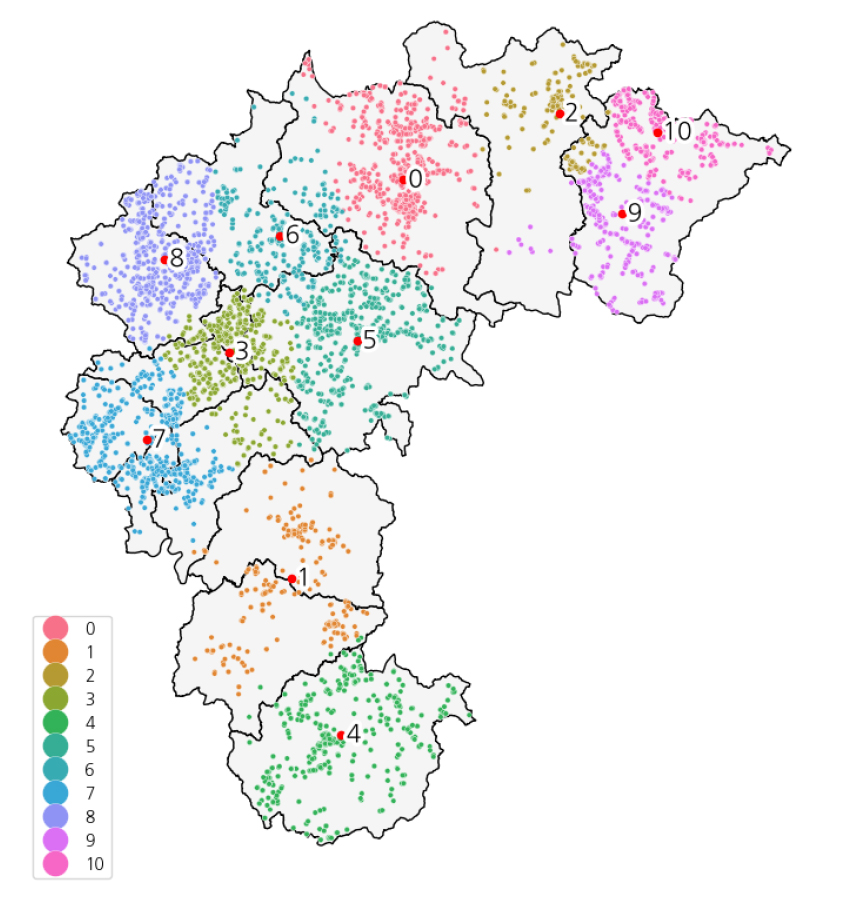
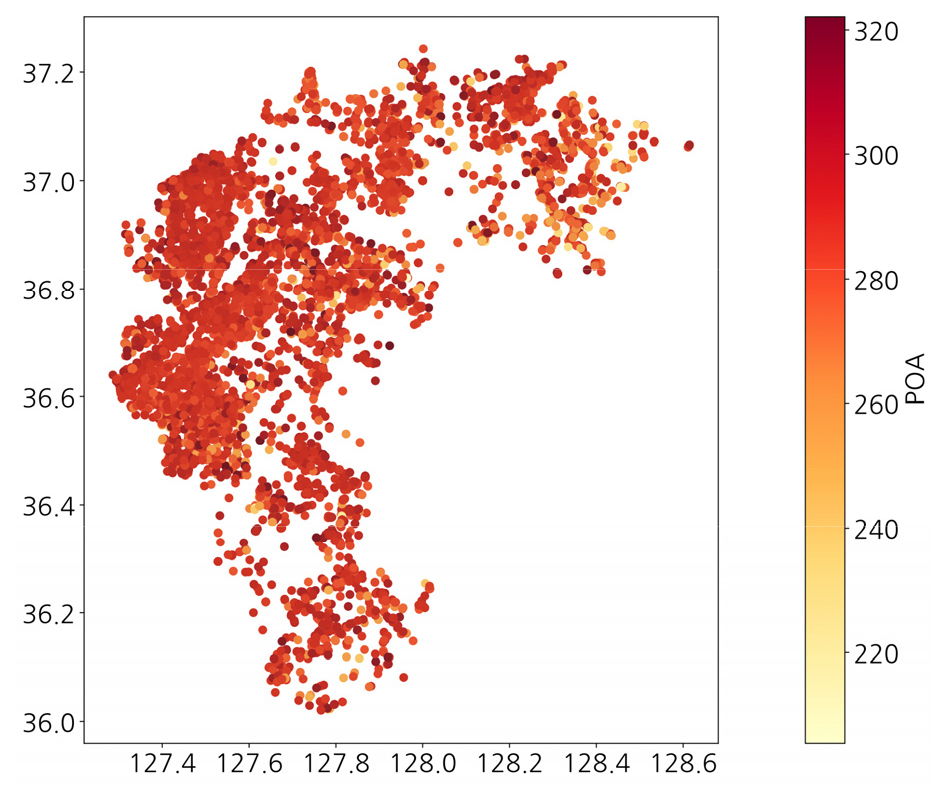
세 번째로, 경사면 도달 일사량을 활용하여 지형 효과를 고려하였다. 일사량 데이터는 국립기상과학원에서 생산한 데이터로 5년간 평균(2016.7.1. ~ 2021.6.30.)을 산출한 자료이며, 해상도는 100 m이다11). 일사량 데이터와 태양광 설비 위치를 반영한 결과를 Fig. 8과 같이 시각화 하였다. 일사량 데이터 또한 다른 인자들과 스케일을 맞추기 위해 정규화하고, K-means 클러스터링을 수행한 결과 최종적으로 8개의 군집을 Fig. 9와 같이 도출하였다. Fig. 7의 결과와 마찬가지로 충청북도의 단양군 지역에는 두 클러스터(2번과 5번)의 영역이 겹쳐 있어 중심점이 가까이 위치해 있음을 확인할 수 있다. 다시 정리하자면 2번과 5번의 중심점은 위경도 상으로는 인접하지만 고도와 일사량의 특성이 달라 서로 다른 클러스터를 이루고 있으며, 이러한 과정을 통해 충청북도 태양광 설비에 대한 지형적 특성을 고려한 클러스터링 결과를 얻을 수 있었다.
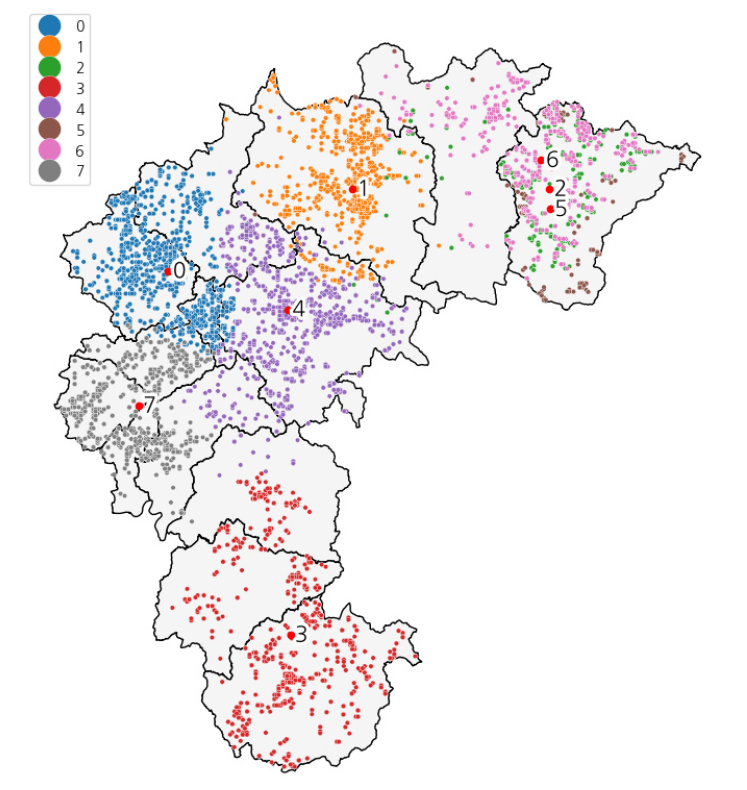
3.2 발전량 히스토리를 활용한 클러스터링 결과
발전량 이력 분석에는 REMS에 연동된 충청북도 지역의 태양광 설비 11,268개의 2023년 1월 1일부터 12월 31일까지의 시간대별 발전량 데이터를 활용하였고, 스케일을 동일하게 조정하는 정규화 작업을 수행하였다. 앞서 정규화하는 과정에서 제시한 산식을 활용하여 변수 값의 범위를 [0, 1] 사이로 조정하여 보면 Fig. 10과 같이 최대 높이가 1인 종 모양의 그래프로 표현된다. Fig. 10 좌측 그래프는 REMS에 연동된 충청북도 지역의 태양광 설비를 K-means 클러스터링으로 군집화하여 찾은 8개의 군집 중에서 임의로 선택한 군집 하나의 설비별 발전량 패턴을 그린 것이다. Fig. 10 우측에 발전 이용률을 box-and-whisker diagram으로 시각화하였다. 이를 통해 정상범위에 있는 설비와 고장, 통신장애, 장비교체 등의 이유로 발전량이 너무 높거나 낮은 이상설비는 눈에 띄게 분리되어 있음을 확인하였다. 본 연구에서는 2장 클러스터링 방법에서 제시한 REMS에 연결된 정상설비 기준(10.01% ~ 22.21%)을 참조하여 이에 해당되는 설비 대상으로 발전량 패턴 클러스터링을 진행하였다9). 정상 이용률 범주에 있는 설비의 발전량 패턴 클러스터링에서는 Autoencoder를 사용(파라미터 값은 Table 4 참고)하여 데이터를 낮은 차원(8차원)으로 압축했다가 원래 차원(24차원)으로 복원함으로써 노이즈가 제거된 중요한 패턴을 추출하고, 이렇게 얻어진 설비별 발전량 패턴에 K-means 알고리즘을 적용하여 클러스터링을 수행하였다. Autoencoder와 K-means를 활용한 결과 Fig. 11과 같이 7개의 군집을 찾을 수 있었다.
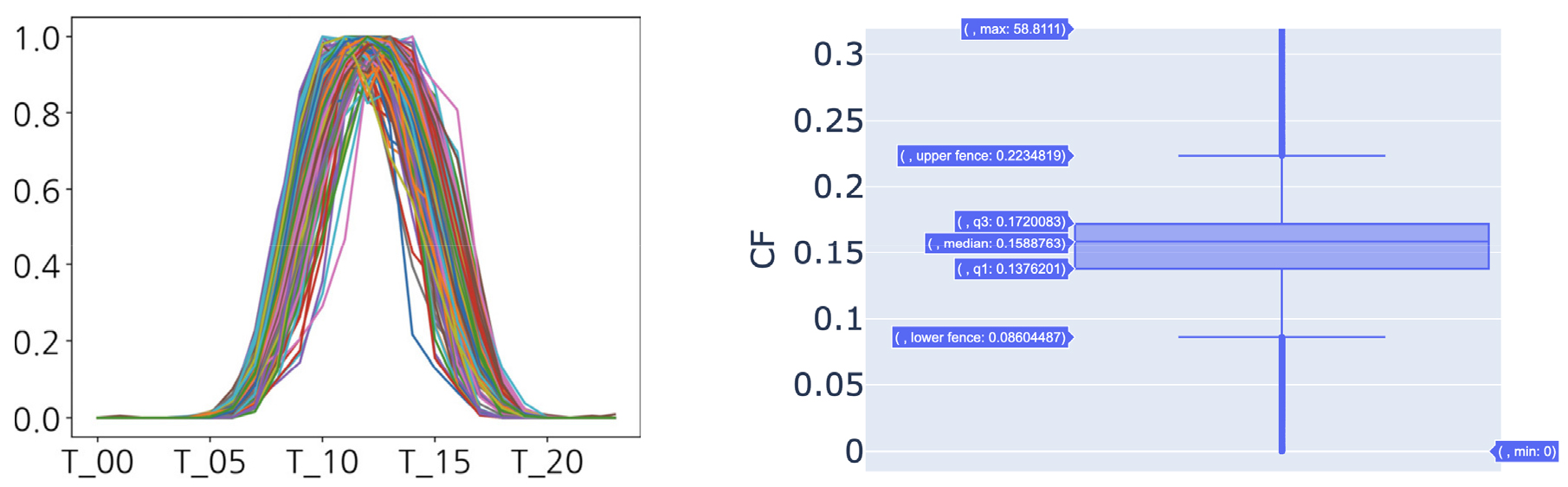
Table 4
Parameters for Autoencoder
Fig. 11의 우측 그래프는 클러스터별 시간당 평균 발전량 패턴을 식(3)으로 정규화하여 시각화한 것인데, 365일 평균치이므로 전형적인 태양광 발전량 패턴인 종 모양(bell shape) 그래프임을 볼 수 있다. 클러스터마다 발전량이 최대치가 되는 시간대(피크 위치)가 다른 것으로 보아 클러스터링이 지리적 위치와 설비의 특성이 비슷한 것끼리 잘 구분하였음을 추측할 수 있다. 태양광 설비의 발전량에 영향을 미치는 요인에는 기상조건을 제외하고 패널의 설치 방향(방위각), 설치 각도(경사각) 등이 있다. 피크 위치가 12시 30분에 있는 클러스터는 패널 설치 방향이 정남향에 가까운 설비들이 많을 것이고, 12시 30분 보다 이른(늦은) 시각에 피크가 위치한 클러스터는 설치 방향이 정남쪽에서 약간 동쪽(서쪽)으로 치우친 설비들이 많이 포함되어 있을 것으로 추정할 수 있다. 클러스터별 시간당 평균 발전량 패턴 그래프의 피크 위치를 비교하기 위한 목적으로 각 패턴을 정규화하여 시각화했으나, 발전 효율 등 다른 성질의 클러스터별 차이를 비교하려는 목적에서는 패턴을 정규화하지 않거나, 전체 패턴을 한꺼번에 정규화하여 시각화하는 것이 더 적절할 것이다.
4. 결 론
태양광 설비들을 지역별로 몇 개의 클러스터로 묶고, 클러스터별로 발전량 예측을 하면, 개별 설비별로 발전량 예측 모델링을 하는 것에 비해 계산 시간과 자원을 절약할 수 있다. 본 연구에서는 이 과정에 기반이 되는 태양광 설비들의 클러스터링에 있어서 적절한 데이터 구성과 알고리즘에 대해 연구하였다. 설비 클러스터링은 두 단계로 구성하였다. 지형적인 요소와 기상 요소를 고려하여 1차 클러스터링(지오 클러스터링)을 수행한 후, 이렇게 찾아진 클러스터별로 다시 발전량 패턴을 기반으로 2차 클러스터링(발전량 패턴 클러스터링)을 수행하였다. 지오 클러스터링에는 설비의 위치(위도, 경도)와 고도를 사용하였고, 기상정보로 일사량 정보를 사용하여 K-means 클러스터링을 수행하였다. 시군구 중심좌표 정보를 사용하면, 시군구 행정단위 경계를 지키면서 군집화할 수 있음도 확인하였으나, 인위적인 경계를 유지하는 것보다는 자연적인 정보만 사용하는 것이 타당하다 여겨 최종적으로 시군구 중심좌표 정보를 사용하지는 않았다. 발전량 패턴 기반 클러스터링 역시 K-means 클러스터링을 활용하였다. 발전량 패턴에는 노이즈가 많이 섞여 있으므로, Autoencoder를 활용하여 노이즈를 제거한 후에 K-means 클러스터링을 수행하였다. 찾아진 군집들이 설비 설치 방향 차이에서 기인하는 발전 패턴 차이를 잘 반영하고 있음을 군집 별 발전량 패턴의 피크 위치가 서로 차이나는 것으로 확인하였다.
본 연구에서는 REMS에 연결된 충청북도 태양광 설비 11,268개를 클러스터링하는 과정에서 위도, 경도, 고도, 일사량의 여러 인자를 동일한 범주로 스케일하는 정규화 과정을 진행하였다. 또한 K-means의 적정 클러스터 수를 정하기 위해 return ratio 개념을 도입하고 시험을 통해 기준 값을 0.91로 설정하였다. 이러한 방법으로 충청북도 지역의 지오 클러스터링을 수행한 결과 8개의 클러스터로 구분되었다. 다음으로 2023년 연간 태양광 발전 이용률을 활용하여 정상 설비를 구분해 내고, 이를 바탕으로 전량 패턴 기반 클러스터링을 진행하였으며 Autoencoder를 활용하여 노이즈를 제거하고 8차원으로 낮춰서 K-means를 진행한 결과 패널의 설치 방향, 설치 각도에 따라 7개의 클러스터로 나타났다. 향후 연구에서는 다양한 기상 예측 데이터와의 접목, 딥 러닝 기반 알고리즘 활용 등을 통해 연구 결과를 더욱 발전시키고 실제 적용 가능성을 높여야 할 것이다. 또한, 발전량 예측기술을 활용하면 시간별 발전량 예측량과 실제 발전량을 비교하여 일정 수준을 벗어난 경우 고장으로 의심할 수 있어, 실시간 고장 또는 이상 상태를 감지하는 데에도 활용할 수 있을 것이다.
