

1. 서 론
기후 변화 대응과 지속 가능한 에너지 전환을 위한 전 세계적인 노력이 강화되면서 태양광 발전은 대표적인 재생에너지 기술로 자리 잡고 있다. 2023년 기준 전 세계 신규 태양광 발전 용량은 약 444 GW로 전년 대비 76% 증가하며 사상 최대치를 기록했다. 이중 중국은 270 GW를 설치하여 전체의 61%를 차지했고, 미국은 약 40 GW, 유럽은 59 GW를 추가하였다1). 국내에서도 2023년 기준 약 28 GW의 누적 설치량을 기록하고 있으며, 정부의 정책적 지원과 기술 발전에 따라 태양광 발전소의 보급은 지속적으로 증가할 전망이다. 이러한 확산은 전력 생산의 탈탄소화 및 에너지 자립을 촉진하는 핵심적인 수단으로 기능하고 있다.
그러나 태양광 발전 시스템의 대규모 확산과 더불어 시스템의 운영 효율성 확보와 유지보수의 지능화가 중요 과제로 부각되고 있다. 태양광 모듈의 성능 저하 및 고장은 발전 효율을 감소시켜 경제적 손실로 직결될 수 있으며, 이는 기후 조건, 오염물 축적, 제조 결함, 설치 오류, 외부 충격 등 다양한 복합 요인에 의해 발생한다. 특히 설치 이후 시간이 경과함에 따라 모듈의 출력 저하와 고장 발생 빈도가 높아지는 만큼, 사전 진단 및 정비 시스템의 구축이 절실한 상황이다. 최근에는 노후 및 불량 모듈의 유형 분류와 장기 신뢰성 평가를 위한 재사용 기술이 활발히 연구되고 있으며, 태양광 모듈의 재활용 활성화를 위해 수명 전 주기에 걸친 이력 관리 체계가 필요하다는 목소리도 높아지고 있다.
정확한 고장진단과 수명 예측을 위해서는 모듈에서 수집되는 시계열 데이터를 정제하고, 이상치(outlier) 및 결측치(missing value)와 같은 오류 요소들을 사전에 제거하는 전처리 과정이 반드시 선행되어야 한다. 센서로부터 수집되는 전류, 전압, 출력 데이터는 노이즈, 통신 지연, 측정 오류 등으로 인해 데이터 품질이 저하될 수 있으며, 이러한 불완전한 데이터를 그대로 분석에 활용할 경우 진단 알고리즘이 오작동하거나 오판단할 가능성이 크다2,3).
기존 연구들 또한 이러한 문제의식을 공유하고 있다. 일부 연구에서는 시계열 데이터의 신뢰도 검증을 위해 이상치 탐지 기반의 정합성 분석 기법을 도입하였으며4), 또 다른 연구에서는 인공신경망 기반의 고장 진단 모델에 전처리 과정을 결합함으로써 진단 정확도를 높이고자 하였다5). 하지만 대부분의 선행 연구는 고장 진단 알고리즘 또는 예측 모델의 성능 향상에 초점을 맞추고 있어, 전처리 기법 자체의 정량적 효과를 비교·분석한 사례는 상대적으로 부족한 실정이다.
이에 본 논문에서는 전처리 단계의 중요성을 강조하며, 표준편차 기반 및 IQR 기반 이상치 제거 기법과 평균값, 중앙값, KNN을 활용한 결측치 보상 기법의 조합을 비교 분석하였다. 각 전처리 조합에 따른 신뢰도(accuracy)를 정량적으로 평가하고, 시각화 결과를 함께 제시함으로써 전처리 방법의 효과성을 직관적으로 확인할 수 있도록 하였다. 본 연구는 고장 진단 및 수명 예측 알고리즘의 데이터 기반 성능 향상을 위한 전처리 기반 기초 연구로서 의의가 있다.
2. 실 험
본 연구에서의 시계열 데이터 전처리는 이상치 제거 및 결측치 보상을 중심으로 수행되었으며, Python 기반 알고리즘으로 구현되었다. 실험에 활용된 데이터는 실제 태양광 발전소에서 수집된 인버터 발전량(Inverter_ kW)을 기반으로, 2024년 11월 13일 하루 동안 10분 간격으로 기록된 데이터를 활용하여 test_1.csv부터 test_10.csv까지 총 10개의 테스트셋을 구성하였다. 각 테스트셋은 서로 다른 발전소에서 수집된 원본 데이터를 통해 만들었으며, 동일한 수집 일자를 기준으로 하지만 일사량, 음영 등 환경 조건에는 차이가 있을 수 있다. 각 파일은 시(hour), 분(minute), 인버터 발전량의 3개 열로 구성되어 데이터의 시계열적 정합성을 확보하였다. Fig. 1은 본 연구에서 수행된 데이터 전처리 과정의 전체 흐름도를 나타낸다.

태양광 모듈의 재사용 및 재활용 가능성을 판단하고, 보다 정확한 수명 예측 알고리즘을 개발하기 위해서는 실환경 기반의 고신뢰성 데이터를 활용한 정량적 분석이 필요하다. Fig. 2는 각 테스트 사이트의 원본 데이터를 시계열 그래프로 시각화한 것으로, x축은 10분 단위의 시간 흐름(Frame Index), y축은 인버터의 실시간 전력 출력값(Inverter_kW)을 나타낸다. 여기서 Inverter_kW는 인버터가 해당 시점에서 출력한 유효 전력(Active Power)을 의미하며, 단위는 kW이다. 이는 누적 발전량(kWh)이나 비율(%)이 아닌 각 시점별 순간 출력 전력값으로, 인버터의 동작 및 발전 패턴 파악을 위한 것이다. 이와 같은 원본 시계열 데이터를 기반으로 전처리 알고리즘의 성능을 정량적으로 평가하기 위해, 동일한 시간 구조를 유지한 상태에서 실측 데이터를 복제하고, 해당 복제본에 인위적으로 이상치 및 결측치 오류를 삽입한 테스트셋을 별도로 구축하였다. 이로써 하나의 원본 데이터로부터 비교 가능한 오류 포함 데이터(Test Input)와 오류 없는 기준 데이터(Evaluation Data)를 동시에 확보하였다. 이상치는 정규분포의 평균값을 기준으로 ±2 표준편차(σ)를 벗어나는 값을 무작위로 설정하였으며, 결측치는 시간의 연속성을 고려하여 불규칙한 간격으로 데이터를 제거하는 방식으로 구성하였다. 전체 테스트셋 내 이상치 및 결측치의 비율은 평균 약 11% 수준으로 설정하였으며, 이는 다양한 오류 조건을 재현하여 전처리 기법의 복원 성능과 데이터 신뢰도를 평가하는 기반 자료로 활용되었다. Table 1과 Table 2는 본 연구에서 사용된 데이터 전처리 서버의 하드웨어·소프트웨어 사양과 테스트 사이트의 위치 및 발전 용량 정보를 각각 나타낸다.
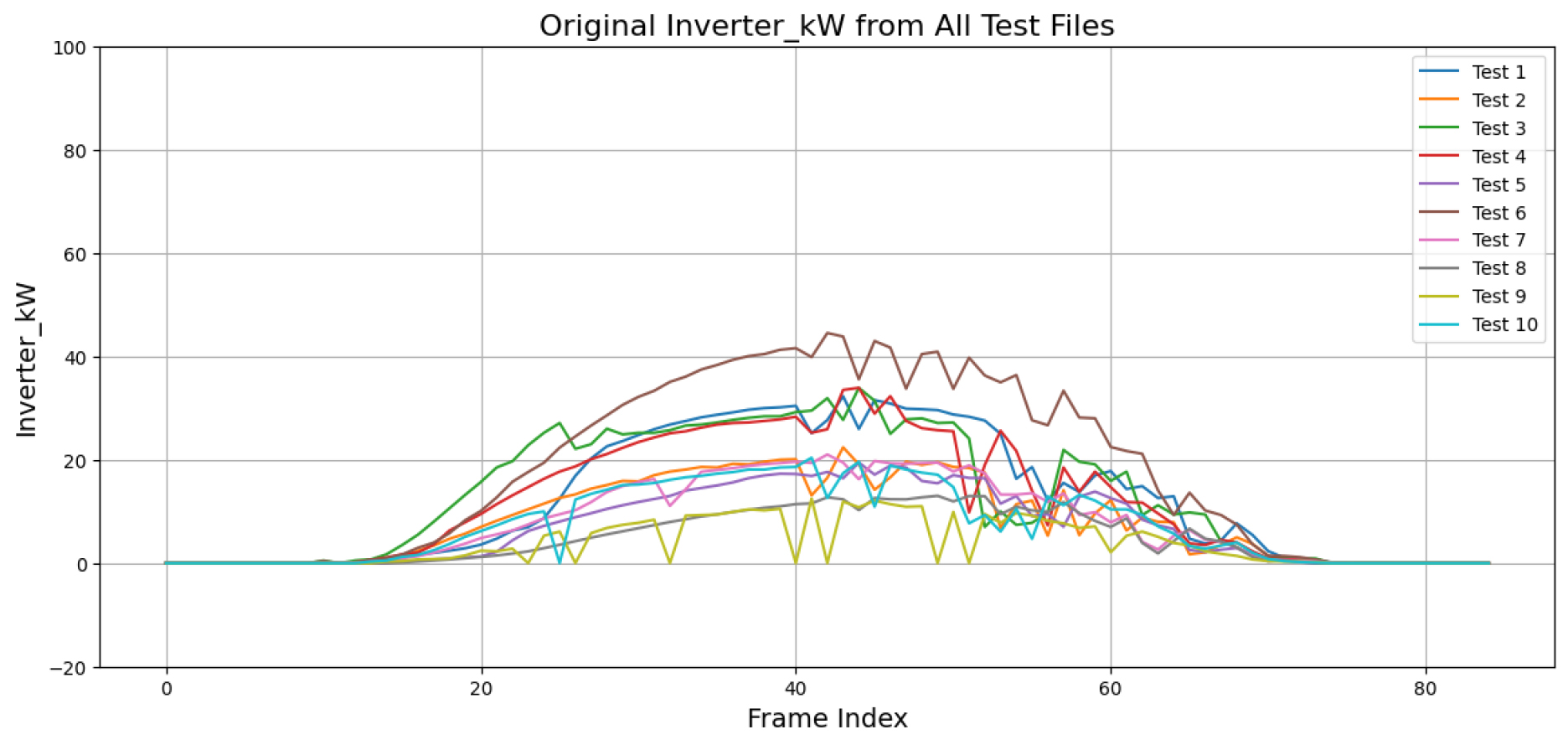
Table 1
Data preprocessing server specifications and software versions
| Hardware | Software | |
| Server | CPU: Intel Xeon Silver 4215R | OS: Ubuntu 18.04 |
| NVIDIA Quadro RTX5000 3 ea | Python: 3.6.9 | |
| RAM : 128 GB | Pandas: 1.5.3 | |
| SSD : 1.92 TB | Sklearn: 1.2.1 |
Table 2
Test site information
3. 결과 및 토의
태양광 발전 시스템에서 수집되는 시계열 데이터는 다양한 물리적, 환경적, 전기적 요인으로 인해 품질 저하가 발생할 수 있으며, 이는 고장 진단 알고리즘의 신뢰성을 크게 저하시킬 수 있다. 따라서 신뢰도 높은 고장 진단 및 수명 예측 알고리즘의 구현을 위해서는 데이터 전처리 단계에서 이상치 제거와 결측치 보상이 필수적으로 수행되어야 한다6). 본 절에서는 이상치 및 결측치가 발생하는 원인과 각각의 전처리 방법에 대해 기술하고, 본 연구에서 최종적으로 제안하는 표준편차 기반 이상치 제거 + K-최근접 이웃(KNN) 기반 결측치 보상방식의 구현 세부 및 평가 기준에 대해 자세히 서술한다.
3.1 이상치 제거
이상치는 정상적인 센서 동작 또는 시스템 운전 범위를 벗어나는 값으로, 센서 고장, 통신 오류, 전력 계통의 일시적 불안정 등의 다양한 원인으로 인해 발생한다. 이러한 이상치를 제거하지 않은 채 고장 진단 알고리즘에 입력될 경우, 정상 데이터를 왜곡하고 오탐률을 증가시킬 수 있기 때문에 전처리의 첫 단계로 이상치 제거는 반드시 수행되어야 한다.
본 연구에서는 이상치 제거 방법으로 두 가지 접근법을 비교하였다. 먼저 표준편차 기반 제거 방식은 데이터의 평균()과 표준편차(STD, )를 기준으로 하여, 전체 데이터 분포에서 크게 벗어나는 값을 이상치로 간주한다. 해당 기준은 다음과 같이 식(1)로 정의된다.
여기서 는 특정 시점의 시계열 값이며, 는 허용 임계 배수로 본 연구에서는 를 적용하였다. 이는 범위 내에 약 95%의 값이 포함된다는 정규분포의 특성을 반영한 것으로, 통계적으로 이상치로 간주할 수 있는 경계 수준을 설정함으로써 과도한 제거 없이 이상값을 안정적으로 탐지할 수 있도록 하였다. 이 범위를 벗어난 데이터는 이상치로 간주되어 결측값(NaN)으로 처리된다. 해당 방식은 시간 흐름에 따른 급격한 출력 상승 또는 하강 등 비정상적인 스파이크를 효과적으로 제거하는 데 유용하다.
한편, 사분위수 기반 제거 방식은 데이터의 사분위수(Q1, Q3)를 활용하여 이상치를 탐지하는 방법이다. 제1사분위수보다 작거나 제 3사분위수보다 큰 값을 기준으로 이상치 판단 범위를 설정하며, 일반적으로 Interquartile Range (IQR)의 1.5배를 기준으로 사용한다. 수식은 다음과 같이 식(2)로 나타낸다.
해당 방식은 데이터가 정규분포를 따르지 않더라도 적용 가능하다는 장점이 있으나, 실제 고장 신호가 포함된 일부 패턴이 제거되는 부작용이 발생할 수 있었다. 이에 따라 본 연구에서는 비교 실험에는 포함하되, 최종 전처리 조합에는 포함하지 않았다.
Fig. 3은 Test 1 데이터에 대해 IQR 기반과 표준편차 기반 이상치 제거를 적용한 결과를 나타낸 것이다. (1-a)는 원본 입력 데이터를 보여주며, (1-b)는 IQR 방식을 적용한 결과로, 일부 극단값이 제거되었지만 여러 이상치가 여전히 남아 있음을 확인할 수 있다. (1-c)는 표준편차 방식을 적용한 결과로, IQR 방식보다 더 많은 이상치가 제거되어 전체적인 분포 곡선이 매끄러워지고 스파이크가 현저히 감소하였다. 이는 두 방식의 통계적 기반 차이에서 기인한다. IQR 방식은 사분위수를 기반으로 한 국소 통계 접근으로, 이상치가 넓은 범위로 퍼져 있는 경우 제거 효율이 낮아질 수 있다. 반면 표준편차 기반 방식은 평균과 분산을 고려한 전역 통계 접근으로, 범위 내에 약 95%의 정상값이 포함된다는 정규분포 가정을 바탕으로 이상치를 안정적으로 식별할 수 있다.

3.2 결측치 보상
이상치 제거 단계 이후에는 다수의 결측 구간이 발생하게 되며, 이 상태로는 분석 및 예측 알고리즘에 입력될 수 없다. 따라서 전처리의 두 번째 단계로 결측치 보상(imputation)이 필요하다. 본 연구에서는 평균 보상, 중앙값 보상, KNN 보상 세 가지 기법을 적용하여 그 효과를 비교하였다.
가장 단순한 기법인 평균값 보상 방식은 전체 데이터의 평균을 기준으로 결측값을 대체하는 방법이다. 계산이 간단하고 직관적인 장점이 있으나, 이상치에 민감하며 시계열 데이터의 흐름이나 주기성 정보를 반영하지 못하는 단점이 있다. 중앙값 보상 방식은 평균값보다 이상치의 영향을 덜 받는 중앙값을 활용하여 결측치를 채운다. 이는 IQR 기반 이상치 제거 방식과 결합할 경우 통계적 일관성을 유지할 수 있다는 장점이 있으나, 시간적 변동성과 상관관계를 고려하지 않는다는 한계가 존재한다. KNN 보상 방식은 결측 구간의 데이터를 유사한 시점의 특성들과 비교하여, 가장 가까운 이웃들의 평균 값을 기반으로 결측치를 예측하는 방법이다7).
Figs. 4 ~ 7은 각 테스트 데이터셋의 결측치 보완 및 이상치 제거 결과를 시각적으로 비교한 것이다. 이를 위해 2행 3열 배열의 그래프를 구성하였으며, 첫 번째 행의 (a)는 테스트에 사용된 결측·이상치가 포함된 시계열 데이터(Test Input)를, (b)는 표준편차 기반으로 이상치를 제거한 결과(STD Outlier Removed)를, (c)는 평가용으로 활용된 Ground Truth 데이터(Evaluation Data)를 각각 나타낸다. 두 번째 행의 (d)는 KNN 알고리즘을 적용하여 결측치를 보완한 결과(KNN Imputation), (e)는 중앙값을 활용한 보완 결과(Median Imputation), (f)는 평균값을 활용한 보완 결과(Mean Imputation)이다.
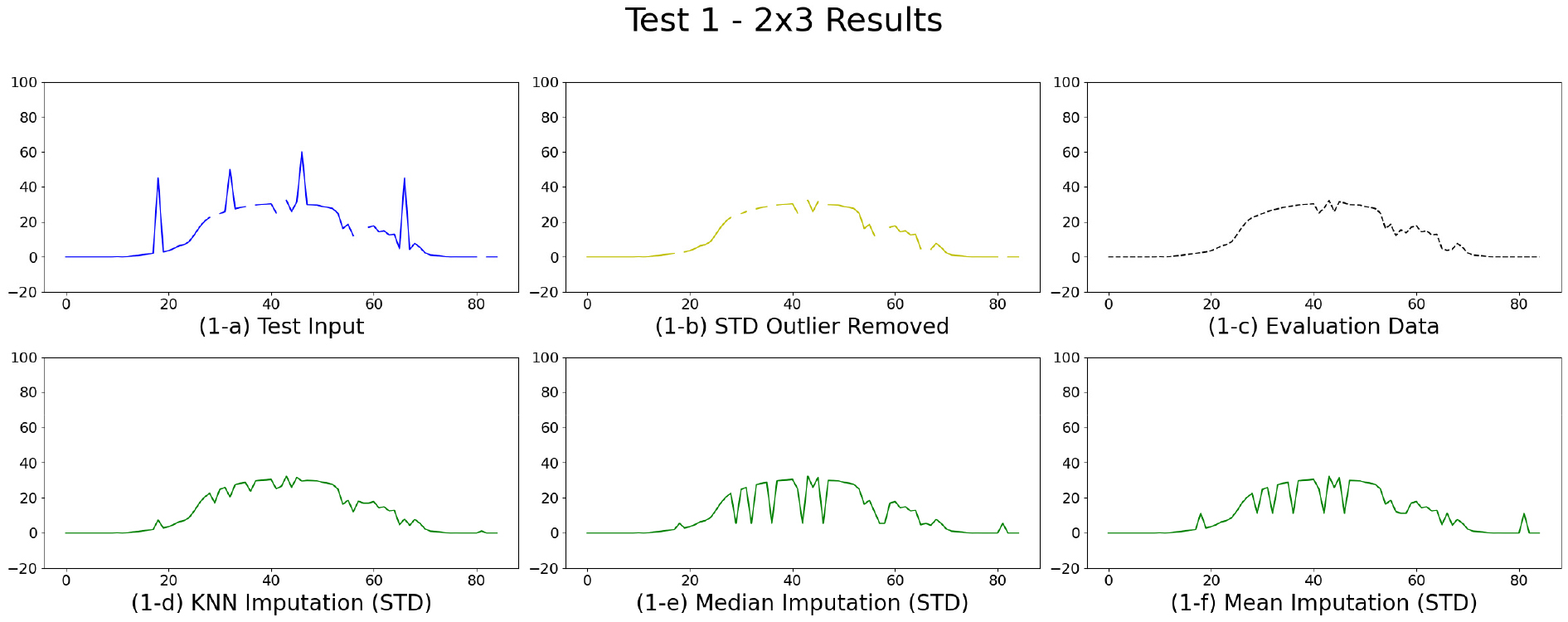
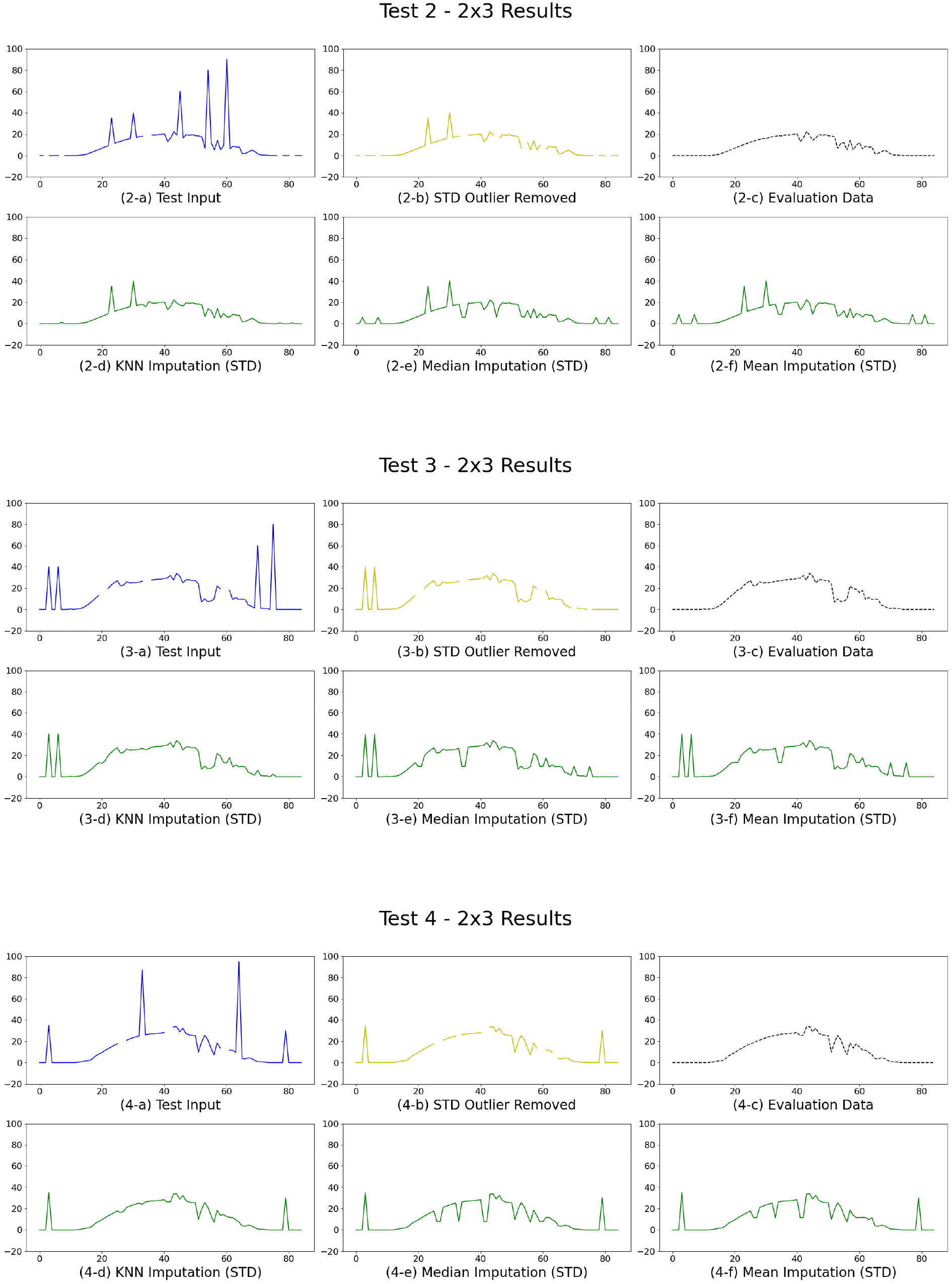
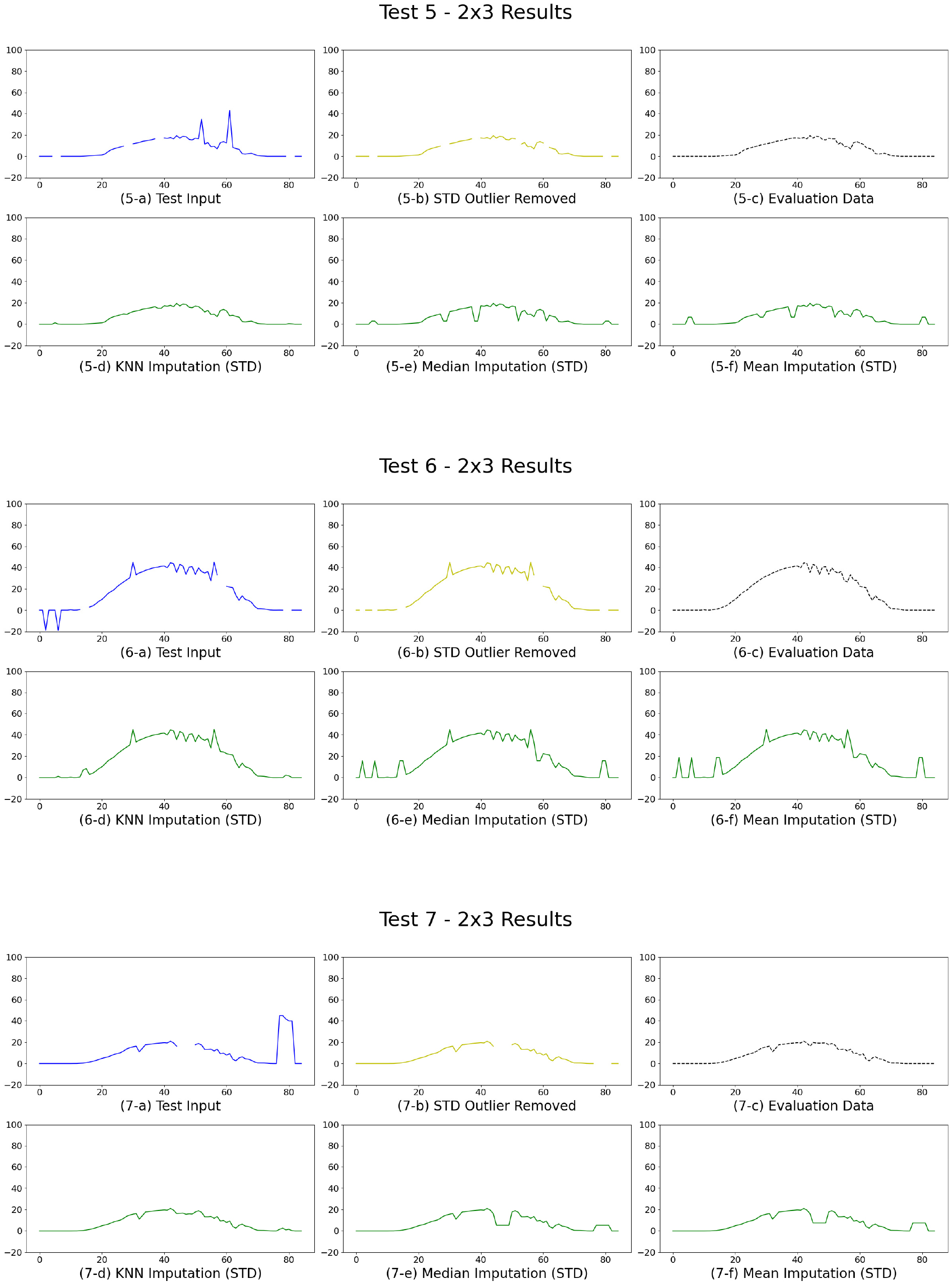
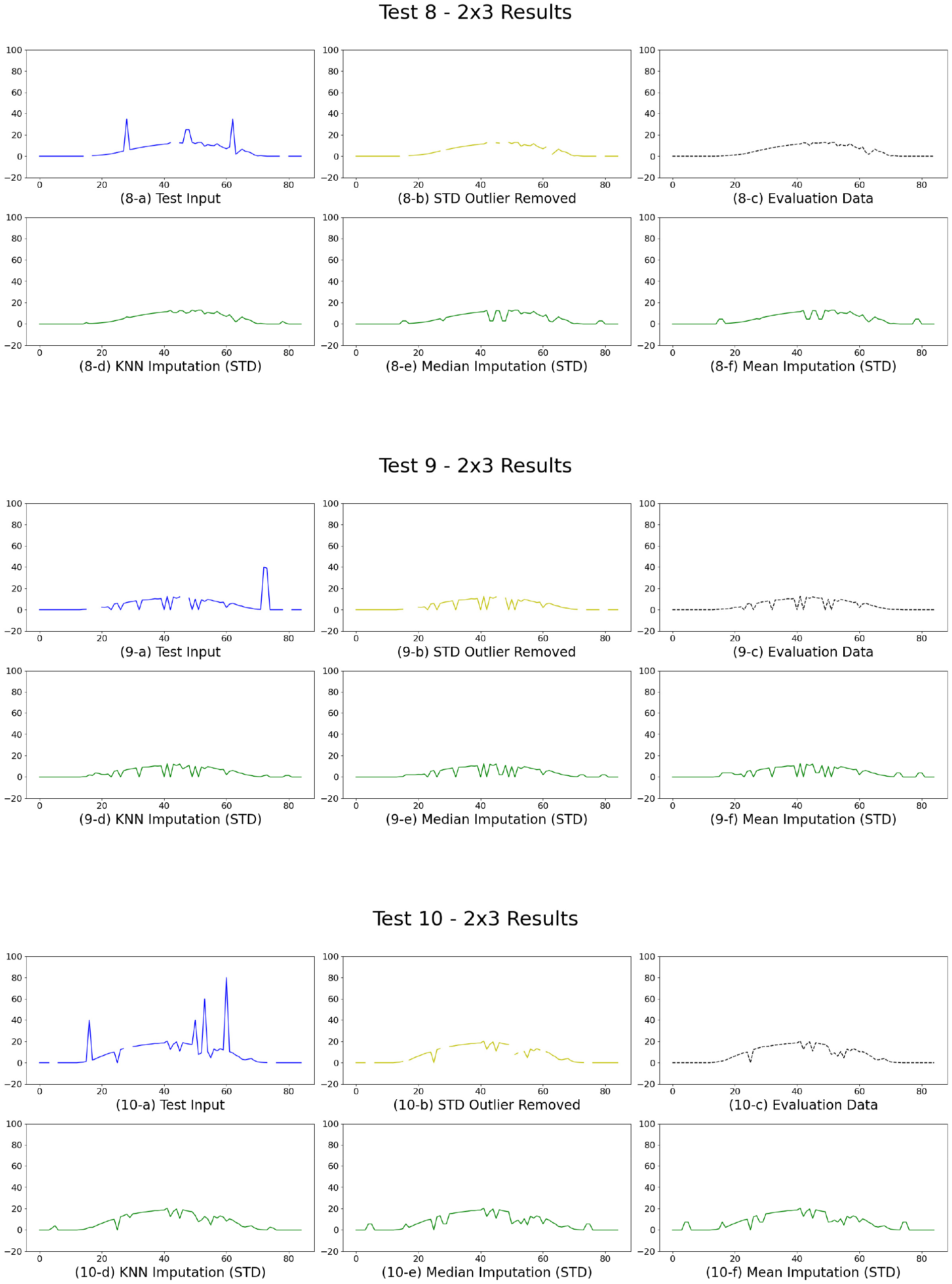
Test 1, 2, 3, 6, 8의 경우, 출력 흐름이 뚜렷한 전형적인 시계열 데이터로, 중간 밀도로 결측 및 이상치가 분포된 양상을 보였다. 이상치 제거 결과는 급변하는 이상치가 효과적으로 제거되어 전체적인 곡선이 안정화되었으며, Ground Truth와 유사한 흐름을 나타냈다. 결측치 보완에서는 KNN 방식이 주변 데이터의 패턴을 기반으로 자연스러운 보간을 수행하여 가장 유사한 결과를 도출한 반면, Median 및 Mean 방식은 결측 구간에 동일한 수치를 삽입함으로써 시계열 특성이 단순화되고 세부적인 추세가 왜곡되는 양상을 보였다.
Test 4, 7, 9는 고빈도 스파이크가 포함된 고노이즈성 데이터로, 결측값도 다수 분포되어 있었다. 표준편차 기반 이상치 제거는 이러한 불규칙 스파이크를 안정적으로 정제하며 원본 시계열의 흐름을 회복하는 데 기여하였다. 특히 KNN 보완은 다수 결측 구간에서 원시 데이터의 고저 추세를 반영하여 복원력을 높였으나, Median 및 Mean 방식은 급격한 변화가 많은 구간에서는 정밀한 복원이 어려워 원본 패턴을 반영하지 못하는 한계를 보였다.
Test 5, 10은 전체 구간에 걸쳐 광범위한 이상치와 결측이 혼재된 상태로, 원본 시계열의 패턴 자체가 거의 식별되지 않는 난이도 높은 전처리 대상이었다. 그러나 이상치 제거와 KNN 보완을 연계하여 적용한 결과, 원본의 완만한 출력 흐름과 유사한 시계열이 형성되었으며, 결과적으로 가장 안정적인 복원이 이루어졌다. 반면, Median 및 Mean 방식은 전체적으로 단조로운 시계열을 생성하며 원본의 변동성과 기울기를 충분히 반영하지 못하는 경향을 보였다.
Table 3은 각 테스트셋을 대상으로 표준편차 기반 이상치 제거 이후, 세 가지 결측치 보상 기법(KNN, Mean, Median)을 적용한 결과를 정량적으로 비교한 표이다. 평균 발전량(Average Power Output)과 발전량의 표준편차(Power Output Std Dev)를 주요 지표로 활용하였으며, 평가용 원본 데이터(Evaluation Data)도 함께 비교 대상으로 포함하였다. 이를 통해 전처리 조합별로 데이터 복원 성능을 수치적으로 평가할 수 있다. 전체 비교 결과, KNN 기반 보간 방식은 평균값 및 분산값 모두에서 평가용 데이터와 유사한 수치를 보이며, 시계열 데이터의 변동성과 패턴을 효과적으로 복원하는 데 유리한 특성을 나타냈다. 반면, 평균값이나 중앙값 기반 보간 방식은 시계열의 동적 특성을 충분히 반영하지 못하는 경향을 보였다. 이러한 결과는 앞서 제시한 Figs. 4 ~ 7의 시각적 비교와도 일치하며, 본 연구에서 제안한 전처리 조합(표준편차 기반 이상치 제거 + KNN 보간 방식)이 고장 진단 및 수명 예측을 위한 신뢰성 높은 입력 데이터 생성을 위해 가장 효과적인 방법임을 정량적으로 뒷받침한다.
Table 3
Comparison table of results by data preprocessing algorithm
3.3 데이터 신뢰도 평가
보상된 데이터의 성능 평가는, 인위적 오류 삽입 전의 원본 실측 데이터를 기준(Evaluation Data)으로 삼아 상대오차를 계산하는 방식으로 수행하였다. 이 원본 데이터는 각 테스트셋과 동일한 시간 축을 공유하며, 결측이나 이상치가 포함되지 않은 상태의 정제된 기준 데이터이다8). 신뢰도는 전체 프레임 수 대비, 상대오차가 일정 기준 이상인 오류 프레임 수의 비율을 기반으로 계산되며, 수식은 다음과 같이 식(3)으로 나타난다.
여기서 는 오류로 판단된 프레임 수이며, 은 전체 평가 대상 프레임 수를 의미한다. 오류 프레임은 전처리된 시계열 데이터와 기준 데이터 간 상대오차가 10%를 초과하는 경우로 정의되며, 수식은 식(4)와 같다:
이 때, 는 보상된 값, 는 실제 기준 데이터이며, 는 0으로 나누는 오류를 방지하기 위한 매우 작은 값이다.
Table 4는 시계열 기반 태양광 모듈 데이터를 대상으로, 세 가지 결측치 보상 기법(KNN, 중앙값, 평균)과 두 가지 이상치 제거 기법(표준편차 기반, IQR 기반)을 조합한 총 여섯 가지 전처리 방식의 성능을 정량적으로 평가하였다. 전처리 성능 평가는 실측 기준 데이터와의 비교를 통해 상대오차가 10%를 초과하지 않는 구간의 비율을 신뢰도(Accuracy) 지표로 정의하여 수행하였다.
10개의 테스트셋을 기반으로 한 실험 결과, 표준편차 기반 이상치 제거와 KNN 보상을 결합한 방식이 평균 96.12%의 신뢰도를 보여, 모든 전처리 조합 중 가장 우수한 성능을 기록하였다. 동일한 이상치 제거 방식에서 중앙값 또는 평균값을 활용한 보상 기법은 각각 평균 95.76, 95.18%의 신뢰도를 보였으며, 이는 KNN 방식에 비해 다소 낮은 성능을 나타냈다. 특히 평균값 보상 방식은 이상치의 영향을 직접적으로 반영하여 일부 구간에서 보정 성능이 저하되는 경향이 확인되었다.
시각적 분석 결과에 따르면, KNN 보상은 결측 구간에서의 데이터 흐름이 매끄럽고 자연스러우며, 정상적인 시계열 패턴을 효과적으로 복원하였다. 반면 중앙값 또는 평균값 보상 기법은 국지적인 고정값에 수렴하는 경향이 있어 시계열 변화가 큰 구간에서는 부적합한 결과를 유도하였다. 또한, IQR 기반 이상치 제거 방식은 이상 탐지 민감도가 높아 상대적으로 정상 구간까지 이상치로 판단하는 경향이 있었으며, 이로 인해 과도한 결측이 발생하여 전체 신뢰도를 저하시켰다. 반면 표준편차 기반 이상치 제거 기법은 전체 데이터 분포를 고려하여 일정 범위 이상 벗어난 값만을 선별함으로써, 실제 고장 신호는 유지하면서 불필요한 노이즈만을 효과적으로 제거하는 데 기여하였다.
결과적으로, 표준편차 기반 이상치 제거와 KNN 보상의 조합은 통계적 안정성과 시계열 보존 측면 모두에서 가장 균형 잡힌 성능을 보였으며, 고장 진단 및 수명 예측을 위한 신뢰도 높은 학습 데이터 확보에 적합한 전처리 방식으로 판단된다.
Table 4
Comparison table of results by data preprocessing algorithm
4. 결 론
본 연구는 태양광 모듈의 고장 진단 및 수명 예측 알고리즘 개발을 위한 시계열 데이터를 대상으로, 이상치 제거와 결측치 보상을 포함한 전처리 모델을 구현하고, 다양한 기법 조합에 대한 성능을 정량적으로 평가하였다. 이상치 제거 기법으로는 표준편차 기반 및 IQR 기반 방법을, 결측치 보상 기법으로는 KNN, 중앙값, 평균값 방식을 각각 적용하여 총 여섯 가지 전처리 조합을 구성하였다. 성능 평가는 실측 기준 데이터와의 상대오차를 기반으로 신뢰도(Accuracy)를 산출하였으며, 그 결과 표준편차 기반 이상치 제거와 KNN 보상을 결합한 방식이 평균 96.12%의 신뢰도를 달성하며 가장 우수한 결과를 나타냈다.
해당 방식은 시계열 데이터의 정상 패턴을 유지하면서도 이상 구간을 효과적으로 제거하고 보상할 수 있는 강점을 갖추고 있으며, 결측이 발생한 영역에서도 연속성과 패턴 보존 측면에서 안정적인 결과를 제공하였다. 특히 결측치 보상이 많아지는 경우, 보상 기법의 선택이 원데이터의 특성과 결과 해석에 중대한 영향을 미칠 수 있으므로 주의가 필요하다. 예를 들어, 평균값이나 중앙값 방식은 일정 수준의 정규화 효과를 제공하나, 과도한 결측에 적용될 경우 시계열의 고유 패턴이 단순화되거나 왜곡될 수 있다. 반면, KNN 방식은 인접 시점의 흐름을 반영하여 상대적으로 유사한 패턴을 복원할 수 있으나, 결측 범위가 길어질수록 보상의 신뢰도는 낮아지는 한계를 가진다. 따라서 결측 발생 비율, 위치, 길이 등을 고려한 보완 전략 수립이 중요하며, 추후 실제 서비스 적용 시 보완 기법에 따른 예측 민감도 변화에 대한 추가 검토가 필요하다. 이러한 전처리 기반은 향후 고장 유형 분류, 열화 추적, 이상 예측 등 다양한 시계열 기반 알고리즘 적용 시 학습 안정성을 높이는 데 기여할 수 있다9). 향후 연구에서는 본 전처리 모델을 기반으로 태양광 모듈의 열화 및 고장 패턴을 분류·예측하는 고도화된 알고리즘을 개발하고, 실시간 진단 시스템과의 연계를 통해 현장 적용 가능성을 검증하는 방향으로 확장해 나아갈 계획이다10).
