

1. 서 론
2. LSTM networks
2.1 LSTM layer
2.2 Bi-directional LSTM layer
3. Hybrid LSTM model for predicting solar irradiance
3.1 Reference model
3.2 Hybrid LSTM models
4. 결 과
4.1 학습 성능
4.2 모델 예측 성능
5. 결 론
기호 및 약어 설명
: LSTM layer에서 가중치 행렬
: LSTM layer에서 편향값을 포함하는 벡터
: LSTM layer에서 후보 셀 상태 값
: BI-LSTM layer에서 순방향 출력 계수
: BI-LSTM layer에서 역방향 출력 계수
: sigmoid function
: input vector at timestep t in LSTM layer
: 시간 t에 대한 측정 일사량
: 시간 t에 대한 예측 일사량
1. 서 론
모델 기반으로 최적 전략에 따라 시스템을 운전하는 model predictive control (MPC)과 관련한 연구는 지속적으로 증가하고 있으며 다양한 연구에서 MPC의 에너지 소비 저감 효과가 확인되었다1,2,3). 한 예로, Building integrated photovoltaics (BIPV) 와 Energy Storage System (ESS) 가 결합한 시스템의 경우 내일의 건물의 에너지사용량을 예측하고, 적절하게 생산된 전력을 저장하거나 전기료가 비쌀 때 이를 방전하는 등의 MPC 전략을 사용할 수 있다4). 이러한 과정에서 시스템의 거동을 묘사하는 모델과 미래의 일사량 예측을 필요로 한다5,6,7). 특히 대부분의 MPC제어의 경우 다음날 운전계획을 선행 계산으로부터 도출하는 방식이므로, 다음날 일사량을 예측하는 것은 중요하다8). 각국의 기상센터에서는 주변의 기상변화에 따라 실측과 다양한 모델을 활용하여 다음날 날씨 정보를 제공하고 있지만, 실제로 MPC에서 필요로 하는 시간단위 일사량을 직접 예보해주는 경우는 매우 드물다9,10,11,12).
따라서, 일사량과 날씨정보의 관계성을 활용하여 다음날의 시간별(hourly) 일사량을 예측하는 모델을 개발하는 것이 필요하다. 기상센터 날씨 예보로부터 일사량을 예측하는 방법 중 최근에는 데이터 학습 기반 모델 중심으로 개발이 진행되어져 왔다. Lago et al.13)의 연구는 임의성이 큰 시계열 데이터의 학습 및 예측에 신경망 구조(ANN, Artificial Neural network)가 유리하다고 발표했으며, Jiang14)의 연구에서도 경험적 물리 일사 예측 모델보다 산경망구조의 예측모델이 정확도가 높다고 보고 하였다. 데이터를 활용하여 학습 기반으로 개발되는 일사예측 모델은 목적에 따라 학습 방법이 다양하다. Sharma et al.15)은 15분마다 모델을 새로 학습하는 일사예측 모델을 개발하였으며, Kemmoku et al.은 Feedforward neural network (FFNN)를 통해 일본 지역의 과거 6년정도의 일사 데이터를 학습해 다음날의 일사량을 예측하는 연구를 진행하였다16). Ahmad et al.17)는 뉴질랜드 일사량 예측에서, 12가지 케이스의 기상 파라미터 조합 실험을 통해 예측에 유리한 최적의 Input parameters 조합을 찾는 연구를 진행하였다. 나아가 Benmouiza and Cheknane18)은 여러 종류의 ANN을 혼합하여 학습하는 일사 예측 모델을 제안하였다.
최근에는 ANN보다 발전된 딥러닝 모델을 활용한 일사 예측 모델 연구가 급격히 증가하였다. 기존의 신경망 구조 학습 방법에 비해 딥러닝 방법은 더욱 복잡하고 상세한 비선형 네트워크 구조를 갖고 있다19). 특히, Hochreiter and Schmidhuber20)으로부터 개발 되어진 LSTM (Long short-term memory)네트워크는 시계열 데이터를 학습하기 유리한 특성으로 인해 일사예측 모델 개발 분야에서 널리 사용되고 있다. Qing and Niu는 기상청의 일기 예보에 기반한 LSTM 일사 예측 모델을 개발하였으며21), Hui et al.은 과거 10년동안 발생한 기상데이터와 일사량을 학습한 LSTM 일사 예측 모델을 개발하였다22). 한편, Jeon and Kim은 대상지역 이외의 다수의 일사량데이터를 정규화하는 방법으로 non local 데이터를 학습해 target local의 일사량을 예측하는 방법을 제안하였다23). 그러나 시뮬레이션을 통해 방법론의 가능성만을 제시할 뿐 실제 예측성능을 테스트하지는 않았다. LSTM 기반의 최신 연구는 Rajagukguk et al.의 리뷰 논문에서 확인할 수 있다24).
최근에는 더욱 개선된 LSTM 모델인 Bi-LSTM이 여러 회귀문제에 적용 되어졌다. Bi-LSTM 네트워크는 순방향(forward)과 역방향(backward) LSTM layers를 구축하여 학습을 진행하기 때문에 기존의 LSTM 알고리즘 보다 더욱 우수한 예측 성능을 보여주었다25). 최근 Bi-directional LSTM (Bi-LSTM)은 다양한 분야에서 사회, 공학적 문제를 해결하는데 활용 되어지고 있다. COVID-19의 향후 사례를 예측하는 모델이 제안되어 졌으며26), PM 2.5 수준 미세먼지 예측에도 Bi-LSTM layer가 적용되었다27). 또한, 해외에서는 변동 전력 요금을 예측하거나28), 풍속을 예측하는 등29) 다양한 산업 분야에서도 Bi-LSMT layer가 적용되었다. Peng et al.에 따르면 Bi-LSTM은 최근 여러 분야에서 시계열적 데이터를 학습하고 예측하는데 사용되어져 왔지만 일사량을 예측하는 모델로 그 성능이 테스트된 사례는 없다30). 비교적 최근인 Peng et al.의 연구30)와 Jaihuni et al.의 연구31)에서 Bi-LSTM 기반의 short-term 일사예측 모델 개발 연구가 이루어졌다. 해당 논문에 따르면 Bi-LSTM based 일사예측 모델은 연구에서 제안한 비교 케이스 보다 우수한 일사 예측 성능을 보였다. 이렇게 일사 예측에서 새로운 LSTM layer를 적용하는 시도는 성능 개선에 대한 가능성을 보여줄 수 있다. 그러나, 해당 연구는 대상지역의 과거 일사량 데이터를 활용하는 일반적인 방법론을 사용하기 때문에 데이터가 부재한 대상지의 MPC를 위한 입력 값 예측용으로는 사용의 한계가 있다.
따라서 본 연구에서는 매우 드물게 연구되었던 Bi-LSTM layer 와 일반적으로 일사예측에 활용되었던 LSTM layer를 혼합하는 Hybrid LSTM layer를 제안하여 일사 예측 모델을 새롭게 개발하고자 한다. 특히 선행 연구에서23) 시뮬레이션을 통해 가능성을 제시한 모델과 유사한 방식으로, 과거 데이터가 부족한 지역에서 사용이 가능할 수 있도록 데이터가 풍부한 타지역 일사량을 학습하여 예측을 수행하는 방법을 실제 건물에서 측정된 일사량을 대상으로 테스트를 진행하여 모델의 실용성을 확인하고자 한다.
2. LSTM networks
2.1 LSTM layer
일반적인 딥러닝 구조는 Input layer, Hidden layer, Output layer 이렇게 3가지 layer로 구성된다. 이중 Hidden layer는 학습을 담당하는 신경망 구조로써 Hidden layer의 설정에 따라 모델의 학습 및 예측 성능이 달라지게 된다. LSTM 네트워크는 1977년 Hochreiter and Schmidhuber로부터 개발된 hidden layer의 구성요소이다20). 보고에 따르면 LSTM network는 시계열 특성이 있거나 순서가 존재하는 문제를 학습하는데 뛰어난 성능을 보인다. 따라서 이전 시간 일사 크기가 어느정도 다음 시간에 영향을 주는 일사량 예측에 LSTM network가 주로 활용되었다. LSTM 네트워크는 일반적인 신경망 구조와 동일하게 하나의 Input layer와 다중의 Hidden layer 그리고 하나의 Output layer로 구성되어져 있다. LSTM 모델의 주요 특징은 Memory cells를 포함하는 Hidden layer에 있으며 Memory cell의 구조는 Fig. 1과 같다.
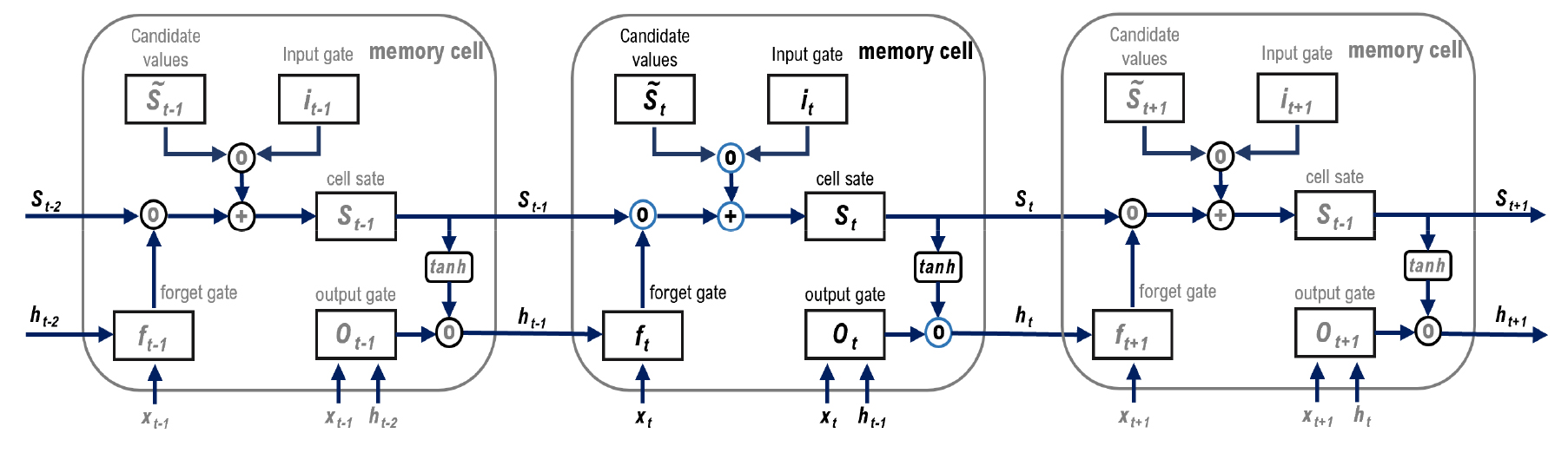
Memory cell은 input gate, output gate, forget gate로 불리는 3개의 게이트를 통해 cell 상태를 유지하거나 조정하며 아래의 식을 통해 주어진 time step t마다 memory cells가 업데이트 되는 과정을 계산한다.
계산된 gate는 최종적으로 현재의 cell state를 결정하는데 활용되며 이는 아래 식으로 계산된다. 여기서 ∘는 같은 크기의 두 행렬에서 동일위치 행렬 Term끼리 곱하는 연산인 Hadamard product를 의미한다.
Output layer 는 current states와 output gate 그리고 active function인 tanh의 곱으로 계산된다. Output layer는 예측 시 coefficient로 사용되며 출력값 와 는 아래 방정식으로 표현된다.
기술된 LSTM networks의 주요 내용과 방정식은 기존 문헌20,32,33,34)을 참조하였으며 보다 자세한 설명은 해당 문헌에서 확인할 수 있다.
2.2 Bi-directional LSTM layer
Bi-directional LSTM(Bi-LSTM)은 기존 forward LSTM layer만을 포함하는 LSTM layer에 backward layer를 추가한 변형된 구조이다. 따라서 Bi-LSTM은 순방향과 역방향 패턴을 동시에 고려하며 시계열 데이터의 경우 이전과 앞선 시간대를 동시에 고려할 수 있다. 이러한 특성으로 전후 문맥이 중요한 언어를 학습하는 분야에서 대표적으로 활용되어지고 있다. Fig. 2는 LSTM과 Bi-LSTM의 구조적 차이점을 보여주는 것으로, 그림에서 알 수 있듯이 Bi-LSTM은 순방향으로만 진행하는 기존의 LSTM계층에 추가로 역방향의 LSTM 계층을 포함하여 양방향 sequence를 갖는 두개의 은닉 계층 상태로 이루어져 있다.
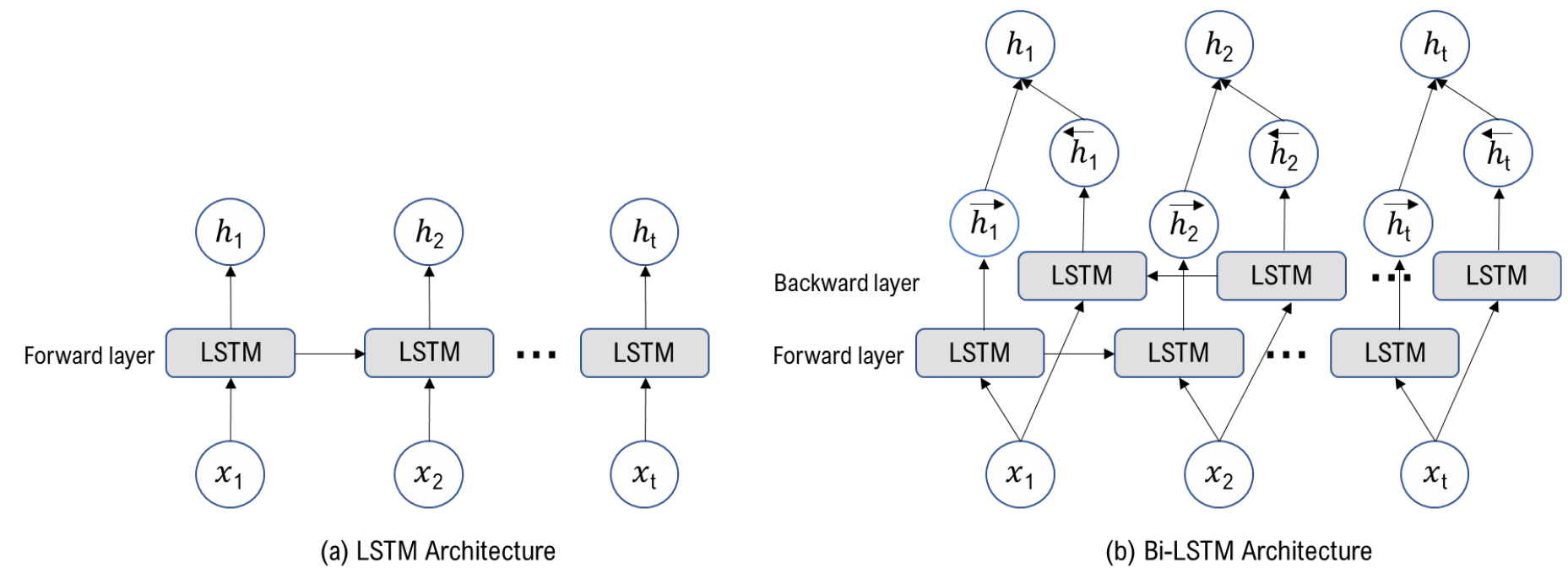
Bi-LSTM은 식(8,9,10)로부터 순방향 와 역방향 가 계산되며 Bi-LSTM의 자세한 내용은 Sun et al., Huang et al., Xu et al.35,36,37)의 문헌으로부터 확인할 수 있다.
3. Hybrid LSTM model for predicting solar irradiance
3.1 Reference model
본 연구에서는 선행 연구에서 개발된 일사 예측모델을 reference model로 선정한다23). Reference 모델은 MPC에 적용하기 위해 개발되어진 LSTM기반 일사예측 모델이다. 모델의 특징은 local 건물의 일사량을 예측하기 위해 non-local 지역의 일사량을 학습하기 때문에 기존에 수집된 기상데이터가 없는 local building에서도 활용이 가능하다는 장점이 있다. Reference model의 다른 특징은 기존의 학습 기반 일사예측 모델은 예측 단계에서 다음날(Day+1)의 일사량을 예측하기 위해 다음날(Day+1)의 기상 예보정보만을 사용하지만, 해당 연구에서는 전날(Day)의 기상 정보를 학습에 사용하여 예측 성능을 개선하는 것이다. 연구에 따르면 전날의 기상데이터는 다음날의 일사 발생과 피어슨 상관계수 0.8 이상의 큰 상관관계를 맺고 있다23). 피어슨 상관계수는 값이 1혹은 –1에 가까울수록 높은 상관을 보임을 의미하는 지표이다. 여기에 일사 발생패턴을 정규화 하였을 때 계절과 지역에 상관없이 모델을 학습시킬 수 있다. 정규화는 하루 중 일사량이 최대로 발생하는 시점을 1로 가정하여 일사 데이터를 재가공 하고, 일조시간은 Day 기준 값이 입력 값으로 제공되기 때문에 Day+1의 일조시간은 입력 값과 유사하게 도출된다. 이러한 과정은 일사 강도와 일조시간이 다르게 나타나는 지역의 일사 패턴을 학습에 이용할 수 있는 아이디어를 제공한다. 즉, 입력 값으로 전날(Day) 의 일사량을 입력하면 정규화된 값으로 학습된 모델의 결과가 전날 일사량 패턴을 기반으로 생성되기 때문에 보편적인 모델로 사용이 가능하다. 본 연구에서도 reference 모델과 매우 유사한 학습 전략을 적용하였다.
다만, 본 연구에서는 학습에 사용되는 모든 일간 일사량의 최대값을 1로 변경하는 대신 1000 W/m2를 나누는 것으로 정규화를 단순화하였다. 이 수치는 대략적인 한국의 일간 최대 일사 발생량을 고려한 것이다. 결정된 하나의 상수로 모델을 정규화 하는 과정은 사용단계에서 명확한 예측 값을 제공할 수 있다. 모델의 사용단계에서는 정규화를 해제하는 과정이 필요한데, 이때 예측하는 날의 일사 최대값을 정확히 아는 것은 불가능하기 때문에 전날의 최대 일사 발생량을 사용해 정규화를 해제한다. 이는 전날의 일사 발생 패턴이 예측결과에 과도하게 영향을 미칠 수 있다. 실제로 흐린 날과 맑은 날이 반복되어 전날과 다음날의 일사 발생패턴이 급격히 달라질 경우 모델의 정확도가 떨어질 수 있다. 하지만 결정된 상수에 기반해 일사량 데이터를 정규화 할 경우 대부분의 일사량은 선행연구와 비슷하게 0과 1사이에 분포하게 되고, 정규화 해제 단계에서도 전날에 발생한 일사 패턴을 사용하는 아이디어는 유지하면서 정규화 해제에 명확한 기준을 제공하여 개선된 예측 결과를 제공하는 것을 기대할 수 있다.
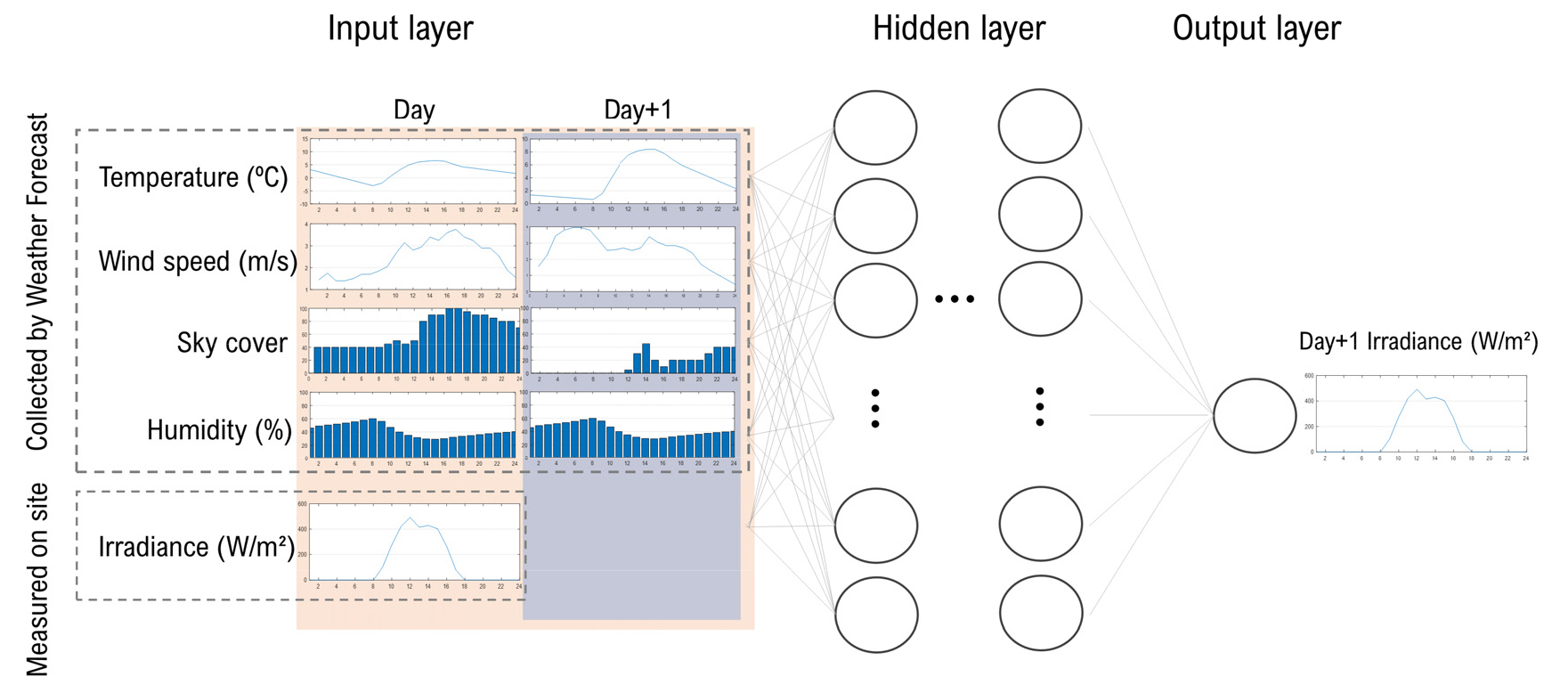
LSTM학습 모델의 Input 및 Output 파라미터는 Fig. 3과 같다. 모델의 입력데이터는 기상청에서 제공하는 외기온도, 운량, 습도, 풍속 그리고 예측 대상 건물의 전날(Day) 일사량으로 하며 출력값은 모델의 예측 목표인 수평면 전일사량(Horizontal irradiance) 으로 한다. 여기서 운량은 하늘의 청명함 수준을 나타내는데 우리나라에서는 매우 맑음, 맑음, 흐림, 매우 흐림 4가지의 카테고리로 예보되어진다. 학습에 사용된 데이터는 일사량의 주기적 특성을 고려해 24시간 단위로 그룹화 하여 학습을 진행하였다. 기상청의 예보 데이터의 경우 hourly 단위가 아닌 주로 3시간 단위의 값을 제공하기 때문에 예보 되지 않은 시간대는 선형보간을 통하여 데이터를 입력하였다.
마지막으로 LSTM 모델은 학습성능을 결정하는 다양한 hyper parameters 및 최적화 알고리즘을 지정해주어야 한다. 본 연구에서 학습 모델에 사용한 파라미터는 Table 1과같다. LSTM 모델은 MATLAB에서 제공하는 딥러닝 툴박스를 이용하였으며38), 최적화 기법으로는 Adaptive Moment Estimation (ADAM)알고리즘을 적용하였다. ADAM 알고리즘은 유동적으로 학습률을 조절하여 단시간에 효율적으로 최적해를 찾는데 유리하다고 알려져 있다39). Reference model은 3개의 LSTM layer를 연속적으로 배치한 Deep-LSTM 구조로 이루어져 있으며 각 LSTM layer는 300개의 Hidden Unit으로 구성되어져 있다. 학습 모델은 Hidden layer와 unit의 가중치를 조절하며 모델의 오차를 최소화한다. 연산은 GPU (Graphics processing unit-RTX 2080ti) 병렬 처리 기술을 사용해 진행하였다. LSTM layer에 적용된 파라미터는 Bi-LSTM layer에도 동일하게 적용되었다.
Table 1
Parameter settings for LSTM and BI-LSTM models
| Parameter | Value | Parameter | Value |
| Opt. algorithm | Adam | Hidden layer | 3 |
| Initial Learn Rate | 0.001 | Hidden Unit | 300 (×3) |
| Execution Environment | GPU | Max Epochs | 200 |
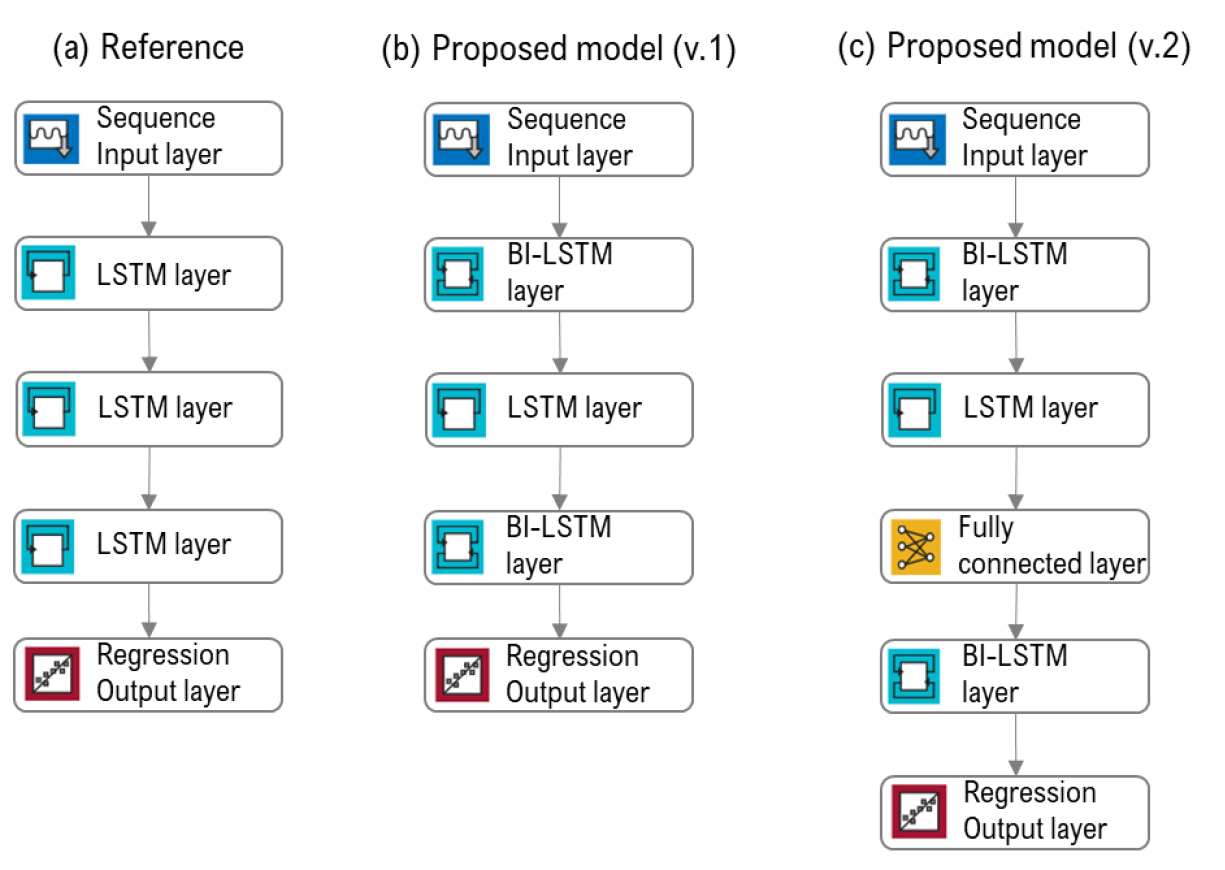
3.2 Hybrid LSTM models
앞서 언급한 Reference모델은 3개의 LSTM layer를 연속적으로 배열해 과거 일사량 발생 패턴을 학습, 예측하게 된다. 여기서 LSTM 모델은 layer의 종류에 따라 모델의 성능이 달라지기 때문에 Reference 모델의 입출력 벡터를 그대로 사용하면서 layer의 종류 및 배열을 수정함으로 예측성능 개선 효과를 기대할 수 있다. Proposed 모델은 단순히 LSTM layer와 Bi-LSTM이 혼합된 Proposed (v.1)과 BI-LSTM layer와 LSTM layer 사이에 Fully connected layer (FC)를 삽입한 Proposed (v.2) 모델로 구분하여 성능을 분석하였다. FC layer는 이전 layer의 모든 뉴런을 다음 layer의 모든 뉴런과 연결해주기 때문에 적절한 배열을 통해 모델의 성능 개선을 유도할 수 있다. 단, FC layer의 배열이 복잡해 질수록 문제나 계산 시간을 과하게 소비하는 문제가 발생할 수 있기 때문에 추가적인 FC layer 삽입은 하지 않았다40). Proposed모델의 학습 파라미터 설정은 Table 1에 기술된 Reference model과 동일하게 하였다. 최종적으로 본 연구에서 테스트할 Reference model 과 Proposed model의 layer 배열은 Fig. 4와 같다. 출력 layer인 Regression output layer 이전에는 학습된 정보를 전달하기 위해 필수적으로 FC layer가 포함되어야 하지만 각 모델 사이의 차이점을 비교하기 위해 그림에서는 표현하지 않았으며 실제 MATLAB에서 구현된 딥러닝 모델에서는 output layer 이전에 FC layer를 포함하고 있다.
본 연구에서 제안하는 일사예측 모델의 실험 프로세스는 Fig. 5에 함께 나타내었다. 여기서 Non-local 지역은 서울, 수원, 강릉, 청주, 대전, 경주, 부산, 광주, 목포로 서로 다른 행정 지역이며 예측 대상이 되는 Local 지역의 대상건물은 인천 지역에 소재한 인하대학교 옥상으로 한다. 학습에 사용된 Non-local 지역 데이터는 기상자료개방포털에서 제공하는 실제 측정된 데이터를 활용하였으며 대상건물의 기상데이터는 기상청의 전날 23시의 기상청 예보와 일사계로부터 수집된 시간별 일사량을 활용하였다. 측정기간은 2020년 11월 5일부터 17일간 실시하였으며, 측정에 사용된 일사계는 Delta ohm사에서 제공하는 LP471PYRA10.5 제품을 사용하였다. 사용된 일사 측정 센서는 ISO9060의 사양 구분에 따르면 가장 상위 등급인 Secondary standard class에 해당한다41). 본 연구에서는 취득이 용이한 데이터를 사용하다 보니 일사량 크기와 패턴이 유사한 데이터를 활용하였지만, 선행연구에 따르면 기후가 완전히 상이한 다른 국가의 global 데이터를 활용하더라도 모델 성능이 크게 감소하지 않았다23).
4. 결 과
4.1 학습 성능
일사예측은 하루단위 예측제어가 이루어진다는 가정하에 예측에 사용되는 모델의 입력데이터를 24시간에 한번 업데이트 되고, 업데이트와 함께 모델 예측을 진행하여 다음 날 24시간의 일사량을 예측하는 형식으로 구축하였다. 모델의 성능은 일반적인 오차평가 방법인 Root Mean Square Error (RMSE)를 통해 모델을 평가하였으며 이는 식(11)과 같다. RMSE 평가 시간대는 가조시간만을 고려했으며, 일사가 발생하지 않는 시간대를 RMSE오차 계산에 포함할 경우 평균오차가 현저히 감소되기 때문에 모델 성능평가의 의미가 떨어질 수 있다.
여기서, 는 시간 t에 대한 측정값을 의미하며 실제 측정된 일사량 데이터를 말하고, 는 예측 값을 의미한다.
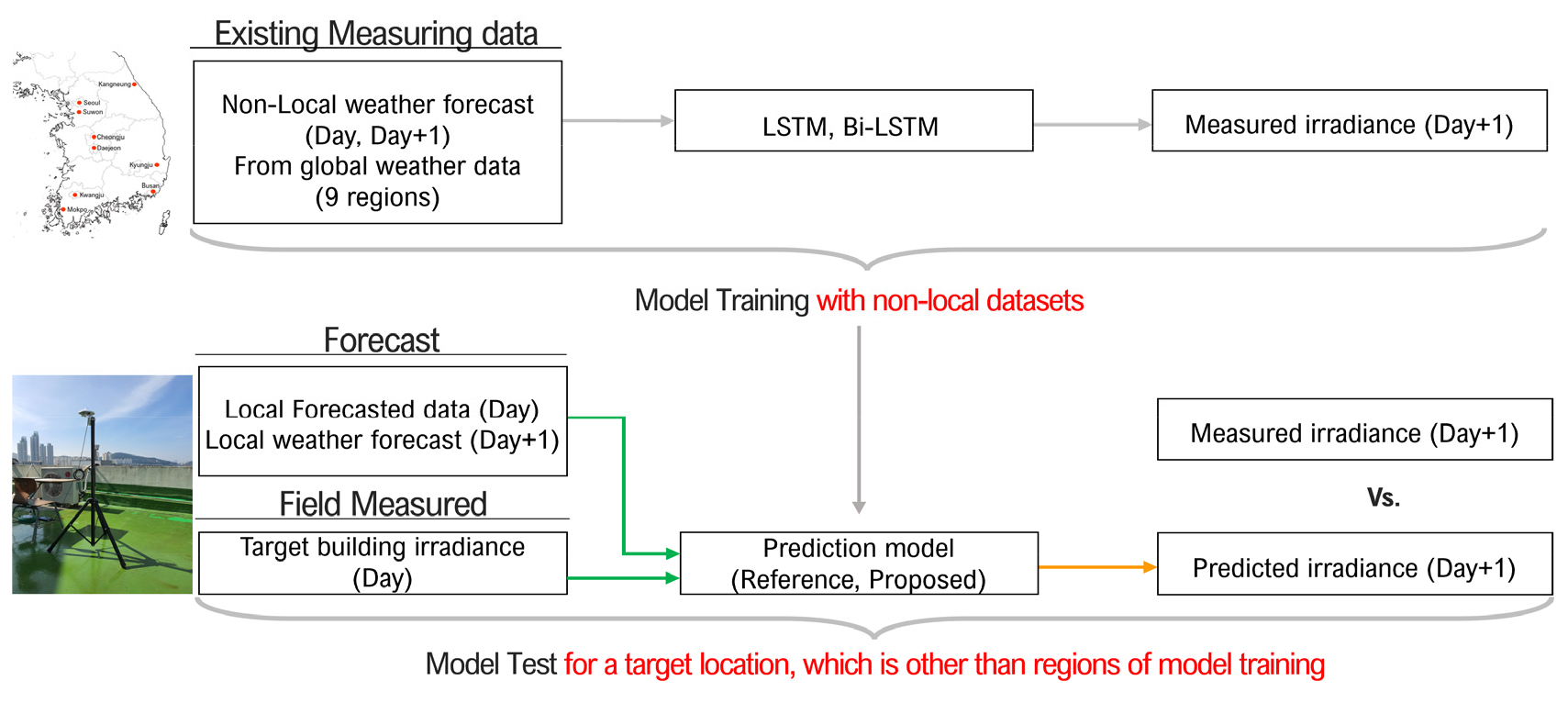
대상 지역을 제외한 9개 지역 일사 데이터를 활용한 모델의 학습 결과는 Fig. 6과 같다. 학습 오차는 LSTM layer로만 이루어진 Reference 모델의 경우 RMSE 15.5 W/m2의 오차율 보였다. BI-LSTM layer와 LSTM layer를 혼합한 Proposed model (v.1) 역시 10.7 W/m2 수준의 오차를 보이면서 두 모델이 비슷한 학습 성능을 보였다. Proposed model (v.2)는 13.9 W/m2 수준의 오차를 보였으며 학습 기간 중 최대 일사 발생량이 1088 W/m2임을 고려하면 3 cases모두 우수한 학습성능을 묘사하고 있다. 산점도는 점들이 대각선에 분포할수록 모델이 정확함을 의미하는데 대부분의 점들이 회색 대각선 주위에 분포하는 것을 확인할 수 있다.
4.2 모델 예측 성능
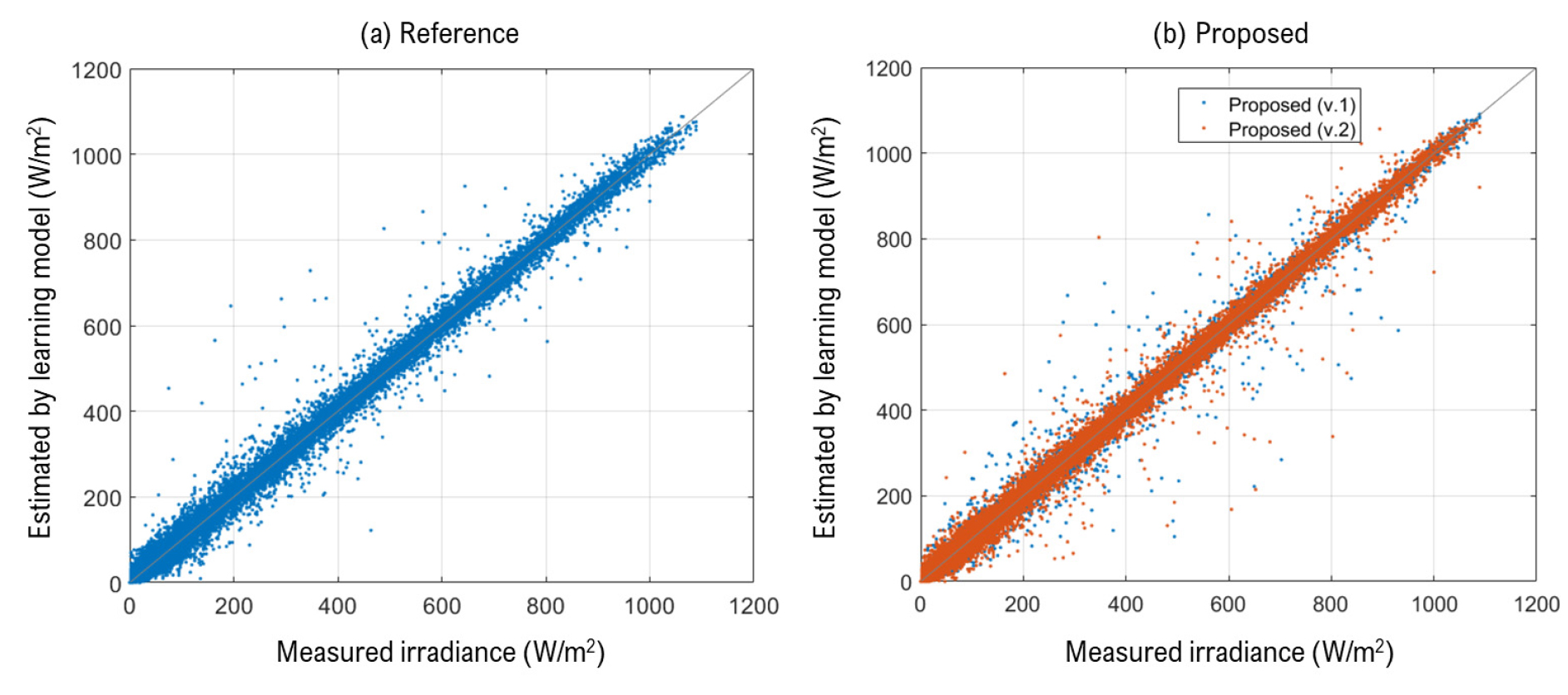
Fig. 7는 11월 5일부터 17일까지 13일동안 Target 위치에서 일사량을 Reference 모델을 통해 예측한 결과와 이때 사용되어진 기상 데이터를 나타낸다. Reference 모델은 일 평균 RMSE 114.1 Wm2의 오차로 일사 발생 패턴은 실제와 유사하게 묘사하였다. 기상데이터의 정확도가 건물 부하에 영향을 주는 정도를 분석하였던 선행 연구에 따르면 일반적인 주거건물 케이스에서 79 W/m2의 수평면 전일사량 오차는 건물 부하에 약 2%의 오차를 발생시킨다는 연구를 참고하였을 때 Target 일사 예측 모델은 MPC 제어에 적합한 예측 결과를 제공한 것으로 판단된다8). 다만, 선행 연구에서는 18 W/m2의 예측성능을 보였는데 이는 실제 측정 데이터가 아닌 TMY2 시뮬레이션 데이터를 사용하였기에 비교적 적은 예측 오차를 보인 것으로 판단된다.
모델의 오차 원인이 기상예보의 정확도에 기인하는 것을 우려하여 기상 예보가 정확함을 가정하였을 때 모델(Reference with perfect forecast)의 성능을 분석하였으며 오차는 RMSE 96.3 W/m2로 조금 감소하였다. 그래프에서 Sky cover는 1에 가까울수록 하늘이 clear한 상태를 의미하며, Cloudy 한 기상 상태로 인해 일사량 발생이 적게 나타나는 11월7일에 큰 오차가 발생하였다. 이러한 패턴의 오차는 Reference 모델이 처음 연구된 선행 연구의 시뮬레이션 결과에서도 동일하게 나타난 것으로 확인되었다23). 테스트가 진행된 날의 기상 예보 정확도와 일사 발생패턴을 보았을 때 기상예보의 정확도와 일사 발생 패턴 사이의 명확한 상관관계를 직관적으로 찾기는 어렵다. 왜냐하면 일사량에 영향을 주는 가장 큰 인자인 운량의 차이가 많이 나는 대부분의 경우에도 Reference와 Reference with perfect forecast 사이의 예측 값이 크기 차이가 나지 않는다. 오히려, 일조시간 전 새벽 시간대에 운량 예측이 다르게 나타난 경우에 두 모델 사이의 차이가 크게 나타나며, 이는 이전 시간대의 입력신호가 일조시간대에도 영향을 미치는 것으로 RNN 계열의 LSTM모델을 사용한 영향으로 보인다. 그러나 전체적으로 기상 예보 정확도에 따른 일사예측 결과 비교하였을 때 기상예보는 일사량 발생패턴에 큰 오차를 주지 않는 수준으로 비교적 정확한 예보 정확도를 보인 것으로 판단된다. 따라서 layer배열에 따른 성능만을 비교하기 위해 이후 진행되는 모델의 분석은 기상데이터가 완벽히 예보됨을 가정한다.
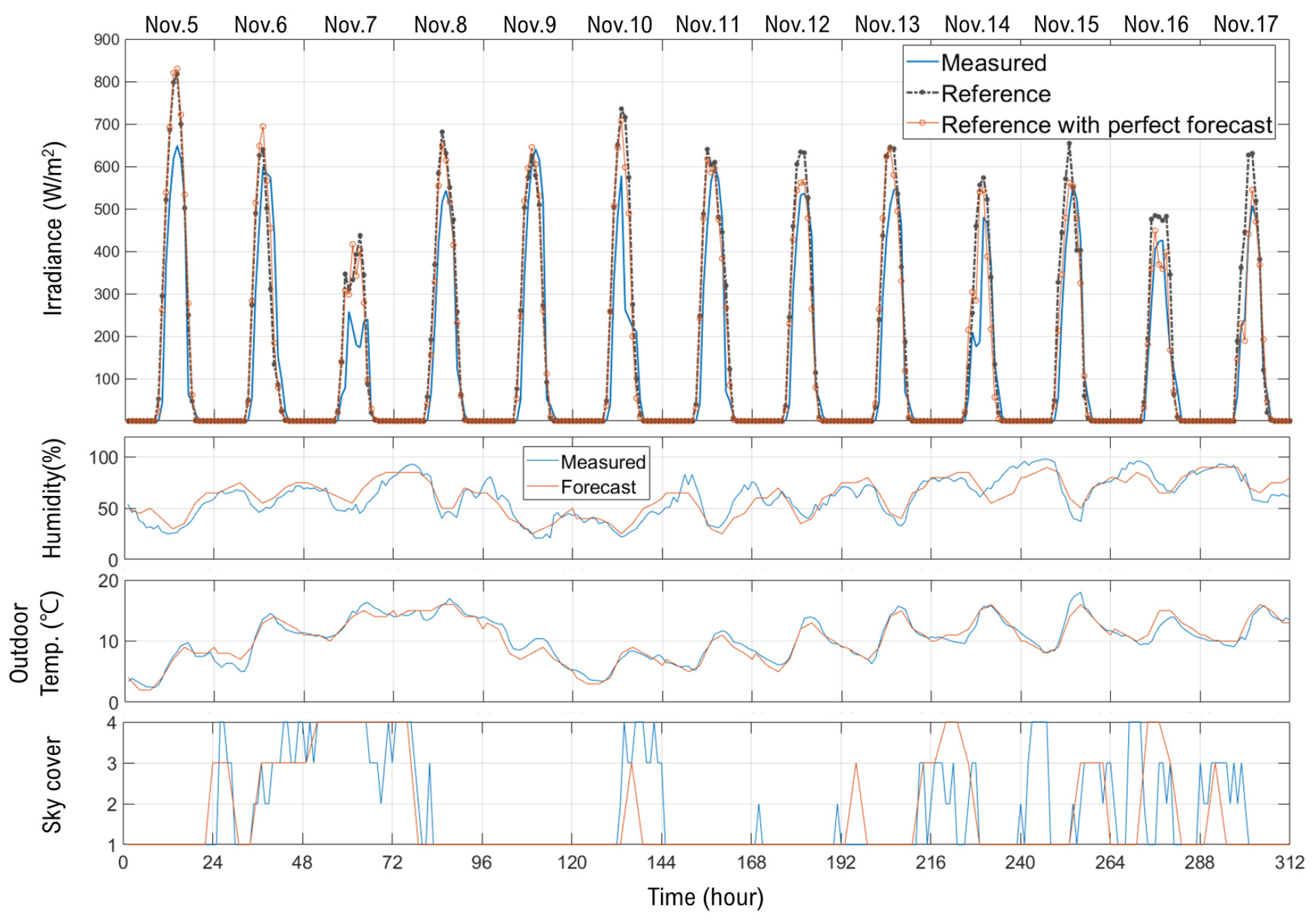
Fig. 8은 proposed 모델의 성능을 의미한다. Proposed 모델은 LSTM layer와 Bi-LSTM이 혼합된 Proposed (v.1)과 BI-LSTM layer와 LSTM layer 사이에 FC layer를 삽입한 Proposed (v.2)모델로 구분하여 성능을 분석하였다. 먼저 Proposed (v.1) 모델은 RMSE 78.3 W/m2으로 Reference 모델 보다 17.9 W/m2 정도 개선된 예측 성능을 보였다. 선행연구의 분석결과를 인용하면 Reference 모델은 hidden layer의 개수가 늘어나는 deep-LSTM 구조일수록 모델의 성능이 개선된다고 발표하였다23). 하지만 본 연구에서 제안된 모델은 reference 모델과 동일한 hidden layer규모를 구축하더라도 적절한 학습 layer 배열 및 종류를 수정하는 것으로 모델의 성능을 개선할 수 있음을 확인하였다.
특히 Reference 모델에서 예측 성능이 크게 떨어졌던 11월 7일에 Reference 모델은 116 W/m2 수준의 오차를 보였으나 Proposed (v.1) 모델은 59.7 W/m2 수준의 오차로 Reference에서 발견되는 특정일에 대해서 과잉예측하는 패턴이 크게 완화되었으며, 이는 11월 5일 예측 결과에서도 확인할 수 있다. 마지막으로 Proposed 모델에 FC layer를 추가한 Proposed v.2의 경우 전체 테스트 기간 동안 RMSE 69.5 W/m2로 가장 우수한 예측 성능을 보였다. 그림에서 알 수 있듯이 두 버전의 proposed 모델은 대부분의 일사 발생 패턴을 실제와 유사하게 묘사하였다.
Fig. 9는 본 연구에서 테스트 된 3가지 케이스의 모델이 테스트 기간인 13일동안의 RMSE 오차를 의미한다. 그래프의 왼쪽은 13일동안 누적된 RMSE를 의미하는데 Reference model은 1252 Wh/m2 수준의 누적 오차를 보였으며 proposed (v.2) 모델은 13일동안 904 Wh/m2로 가장 적은 오차를 보였다. 오른쪽 그래프는 13일동안 하루 중 일반적으로 일사량이 많이 발생하는 시간대인 12시부터 15시까지의 평균 RMSE오차를 의미한다. 제안된 테스트 케이스 모두 발생한 오차의 패턴은 유사하였다. Proposed 모델은 대부분의 구간에서 Reference 모델 보다 감소된 오차를 보였으며 특히 맑은 날 흐린 날 상관없이 냉방부하의 크게 발생하는는 Peak 시간대에서 많은 경우, 보다 정확한 일사량 예측이 가능한 것으로 보인다. 각 분석 cases오차는 Table 2에 정리하였다. 본 연구에서 제안된 Hybrid layer 기반의 Proposed model 은 Reference model 대비 개선된 일사 예측 성능을 보였다. Table 3은 최근에 발표된 LSTM 기반 일사예측 모델 중 Time interval이 hourly이면서 forecast horizon이 1 day ahead인 논문의 예측 성능을 비교한 것이다. 주목하고 싶은 것은 Proposed 모델은 일반적인 예측 모델과 유사하거나 더 적은 Input parameters를 사용하여 LSTM 모델을 학습하고 있다. 또한 일반적인 딥러닝 기반 일사 예측 모델은 예측 지역에서 수집되는 장기간의 누적 데이터를 활용해왔지만 Proposed 모델은 Global 지역의 기상데이터를 기반으로 모델을 구축하기 때문에 단 하루의 측정만으로도 다음날의 일사량을 예측할 수 있다. 마지막으로 모든 선행연구의 예측 모델이 동일한 기상 조건에서 테스트되지 않았기 때문에 모델의 오차를 직접 비교하는 것이 모델의 절대적인 성능을 의미하지는 않는다. 그럼에도 불구하고 Proposed 모델은 선행연구와 유사한 예측성능을 보이는 것으로 확인되었다.
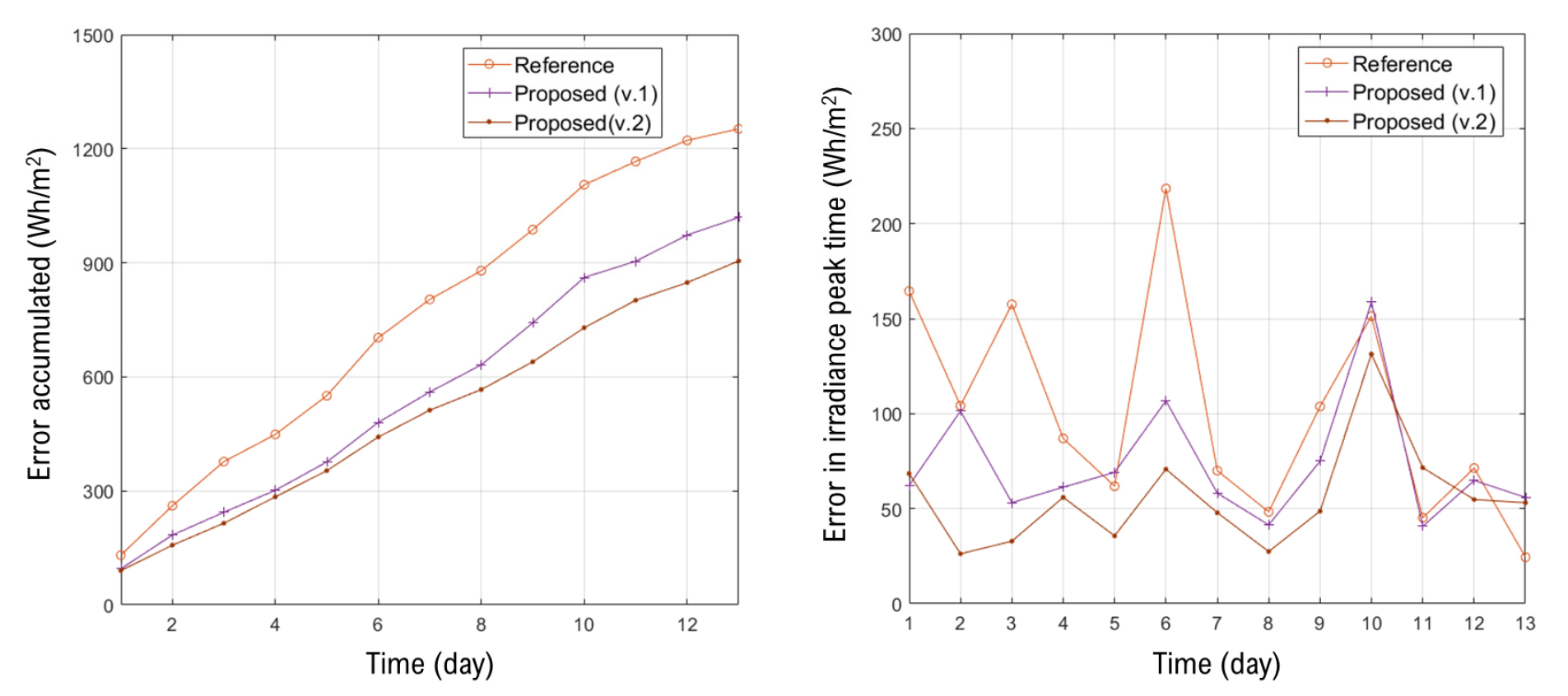
Table 2
Prediction performance of the target models
| Case | RMSE (W/m2) | Accumulated RMSE (W/m2) |
| Reference | 96.3 | 1252.1 |
| Proposed (v.1) | 78.3 | 1019.1 |
| Proposed (v.2) | 69.5 | 904.7 |
Table 3
Performances of previous solar irradiance prediction models
| Case | Input Parameters |
Size of local data required for training | RMSE (W/m2) |
| Qing et al. (2018)21) | Wind speed,Temperature,Humidity,Visibility | 30 months | 76.2 |
| Husein et al. (2019)42) |
Temperature,Humidity,Wind speed,Wind direction,Precipitation,Cloud cover | 140 months | 60.3 |
| Aslam et al. (2019)43) | Solar irradiance | 120 months | 55.2 |
| Hui et al. (2020)22) |
Temperature,Humidity,Cloud cover, Wind speed,Pressure | 120 months | 62.5 |
| Proposed (v.2) | Temperature,Wind speed,Sky cover,Humidity | One day | 69.5 |
하지만 제안된 모델은 다음과 같은 명백한 한계점이 존재한다. 먼저 테스트 기간이 13일로 짧았기 때문에 다양한 기상조건에 대한 예측 결과를 일반화하긴 어렵다. 특히 Hybrid LSTM 모델은 Cloudy한 날씨에 Reference model 보다 개선된 성능을 보이는 것을 확인하였으나 테스트 기간 13일 중 Cloudy 날씨는 단 하루만 존재하였기 때문에 테스트 결과는 일반적인 Cloudy 기상에서의 예측성능을 대표하지 않는다.
또한, 본 연구에서 제안한 Hybrid LSTM 모델은 굉장히 많은 경우의 수의 LSTM, Bi-LSTM layer배열 방법이 존재한다. 향후 다양한 조합법이 제안된다면 모델의 오차는 변경될 수 있으나 본 연구의 목적은 MPC를 위해 Hybrid LSTM layer 기반의 일사예측 방법이 기존의 모델 대비 개선된 성능을 보이는 것을 확인 하는데 있다. 따라서 다양한 Hybrid LSTM 조합 케이스에 대한 폭 넓은 분석은 본 연구의 범위에서는 제외하였다.
5. 결 론
본 연구에서 제안하는 모델 학습은 Non-local 데이터를 통해 local 건물의 일사량을 예측하기 때문에 과거 데이터가 부족하거나 측정기기를 대량으로 설치하기 어려운 중소규모 건물에서 유용하게 적용할 수 있는 기술이다. 모델은 LSTM과 BI-LSTM이 혼합된 Hybrid LSTM layer를 기반으로 개발하였으며, 실제 측정 데이터를 통해 적용 가능성을 평가하였다.
먼저, 기존 LSTM layer 기반의 Reference 모델은 RMSE 96.3 W/m2으로 실제와 유사한 일사 발생 패턴을 묘사하였으며 , 제안 모델인 LSTM 과 Bi-LSTM을 혼합하였을 때 모델(Proposed v.1)의 오차는 78.3 W/m2으로 단순 LSTM layer가 연속적으로 배열된 reference모델과 비교하였을 때 조금 개선된 수준의 오차를 보였다. 이는 동일한 수준의 layer 규모에도 그 배열과 layer 종류에 따라 일사 예측 모델의 성능 개선이 가능함을 의미한다. 추가로 Proposed model에 FC layer를 추가해 Hidden layer의 크기가 한 단계 증가하였을때 모델(Proposed v.2)의 RMSE 오차는 69.5 W/m2으로 더욱 개선된 성능을 보였다. 향후 연구에서는 다양한 Layer 조합 및 학습에 사용되는 global 데이터의 추가를 통해 일사 예측 정확도를 개선할 수 있을 것으로 판단된다.
제안모델의 에러수준은 MPC 일사 예측 적용 시 건물 부하 예측 기준 2% 수준에 해당하는 오차로 예측 제어용으로 활용이 가능하며, 특히 여름철 Peak 시간대에 특히 적은 오차로 MPC의 적용에 유리하다. 무엇보다 정규화된 기상데이터를 통해 모델을 학습하는 장점이 있어 실제 일사 예측이 필요한 건물에서 one day ahead에 측정된 일사량 데이터만으로 기존 일사 예측 모델 수준의 예측이 가능하기 때문에, global 데이터로 잘 학습된 모델을 신축 건물의 MPC 모듈로 바로 사용할 수 있는 장점이 있다.
